
Piggydb at CeBIT 2014 in Hanover
Posted: February 25, 2014 Filed under: uncategorized 3 Comments“Grow Your Knowledge with Piggydb” by Dmitri Popov
– 10 Mar. 2014, 01:00 PM – 01:45 PM
– http://www.cebit.de/event/grow-your-knowledge-with-piggydb-/VOR/57737
Don’t miss it if you will be at CeBIT! It’s a very rare opportunity to hear about Piggydb.
Piggydb V6.17 – Incremental Search by Tag and MathJax Support
Posted: February 16, 2014 Filed under: uncategorized 6 CommentsFirstly, this release extends the fragment incremental search to support tags in addition to keywords. You can add tags for the list to include or exclude the fragments with the specified tags as follows:
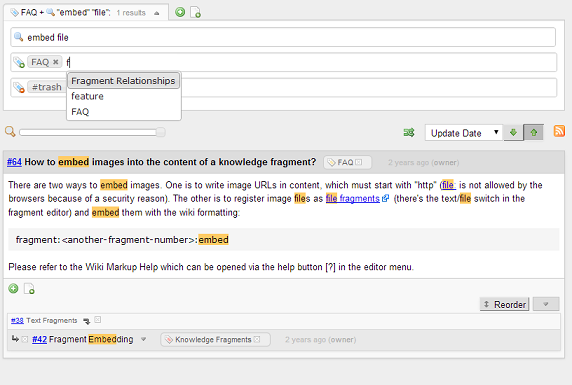
The list will be automatically refreshed as you edit the criteria (keywords, tags). This incremental search is going to replace the filter feature which will be removed in coming versions.
Secondly, the release adds MathJax support that allows you to embed mathematics notation by writing LaTeX expressions in the content:
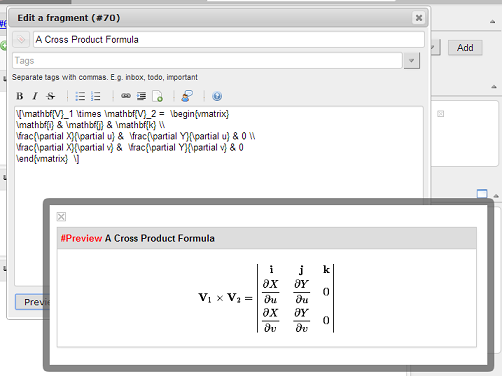
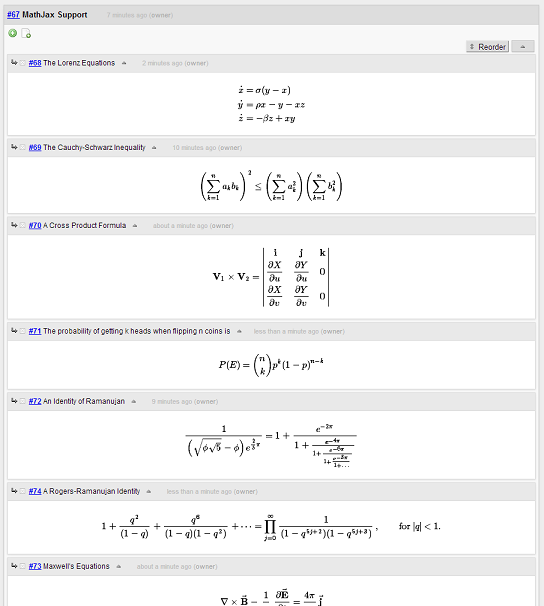
And lastly, the global search box has been cleaned up a little bit, removing the redundant buttons.
You can download the latest version from: https://sourceforge.net/projects/piggydb/files/latest/download
Linux Magazine: Organize and access data with Piggydb
Posted: February 3, 2014 Filed under: media article Leave a comment
Dmitri Popov, a technical writer covering Linux and open source software, wrote an extensive article on Piggydb for Linux Magazine. It covers various topics: what Piggydb is all about, detailed instructions on how to set up and use it, etc.
To be honest, I think it is the best article on Piggydb I’ve ever read. So if you are looking for a definitive guide to enter the Piggydb world, it is definitely worth checking out.
http://www.linux-magazine.com/Issues/2014/160/Workspace-Piggydb
Feature request: Fragment-based filtering
Posted: February 2, 2014 Filed under: discussion 3 CommentsPiggydb user Novbert posted his thought on the problems of Piggydb’s filters on the issue tracker. I think his feedback is to the point and am beginning to think about removing or overhauling the current filter feature in the coming versions of Piggydb.
I’d love to hear from you on this topic, so please post a comment on this article if you have any opinions.
I don’t particularly like the way filters are integrated into the piggydb concept. Actually I think they are part unnecessary and part redundant. One could argue, that they are there as shorthands for any meaningful set of concepts, but we have tags for the very same purpose, rigth? Even if we argue, that there are useful sets of tags we want to leave untagged, that set should probably also be a concept in itself, thus filters should be fragments themselves, shouldn’t they?
Actually this way of thinking also works in the opposite direction. Fragments could be used as filters for the sum of tags assigned to them. Would that be the case, having filters as a separate entity would be totally unnecessary.
Let me tell an example. I’m building a DB on all types of fiction, movies, books, comics, etc. I categorize them based on genre, media, author, etc. Naturally I have tags like Movies, Books, and also Sci-fi, Fantasy. Though having a category for “Sci-fi movies” sounds rather intuitive, how would I do that in piggydb? I don’t want to set it up as a tag, as I already have a set of tags for this, so it would make my tag system redundant by assigning both “Sci-fi” “Movies” and “Sci-fi Movies” tags to all the relevant fragmens. But if I set it up as a filter, I lose the ability to make general notes on the subject. Of course I could solve the problem by creating a fragment called “Sci-fi movies” and assign all the specific movies as child fragments, but that would result an organized list of movies, while I’d like to see these as a set, while making general notes on them (e.g. : the history of Sci-fi movies, notable directors, etc.) I’d like to look at this summary fragment, and edit it, while browsing through all the specific movies.
Which brings me to my next point: the uselessness of the middle and right pane when focusing (clicking) on a non-tag fragment. If I do that, the fragment content appears on the left, leaving a useless view of all my fragments in the middle (which can be filtered by keyword, but not by tags), and a similarly useless right pane, without tag-based filtering ability.
I think it would make much more sense if it would work like this:
– Clicking on any non-tag fragment wouldn’t only show the contents on the left, but it would also make the middle and right pane behave as if I’d have set up a filter with all the tags assigned to that segment. Changing filter parameters would only affect the middle and right pane, the chosen segment would remain active on the left as long as I don’t click on another one.In the above scenario it would result this:
I could set up a non-tag fragment called “Sci-fi movies” and assign tags “Sci-fi” and “Movies” to it. If I click on that fragment, it would appear with all the details on the left, while all the actual sci-fi movies with tags “Sci-fi” and “Movies” assigned would appear on the right, with ability for further filtering based on both keywords, and tags. I could overview all of them, while looking at my summary fragment, and I could even try to find relevant fragments in other categories e.g. by removing Sci-fi from the filter criteria and add another related tag like “James Cameron”. All this, while still looking at my summary fragment called “Sci-fi movies”
Similarly if I’d click on any actual sci-fi movie (e.g. Avatar, with tags “Sci-fi”, “Movies” and “James Cameron” assigned), in the middle pane there would appear all the movies falling in exactly the same category (e.g. Alines, The Abyss and Terminator 2), and I could even try to find related concepts e.g. by removing Cameron from the tag filter criteria and inserting another director.)
As I see this way of working might as well make Filters as separate entities entirely unnecessary for piggydb, as users would have the ability to filter fragments based on tags (as it is right now), and fragments themselves would behave just like filters, thus if the user finds any important pattern/set in the database, he could create a fragment with the relevant tags assigned, making himself able to query that set later on at any time. That later step would even be unnecessary as any set of fragments with the same tags applied would behave like a filter for itself.
What do you think?


Recent Comments