
Piggydb V4.15 released
Posted: September 28, 2010 Filed under: uncategorized 2 CommentsThis release adds Drag-and-drop Tagging, which allows you to drag a tag from the Tag Palette and drop it onto a fragment.
Clicking the tag icon on the right side of the main menu bar shows the Tag Palette:

You can drag a tag from the palette:

And you can drop it onto a fragment:

Download Piggydb V4.15 from https://piggydb.net/
Wiki, Mind maps, Concept maps and Piggydb
Posted: September 24, 2010 Filed under: essay 7 CommentsBefore I created Piggydb, I had been using a Wiki for storing and organizing my thoughts, ideas, article excerpts, and anything else I wanted to write down. Although a wiki provides an extremely simple and flexible way to organize your knowledge in a network structure, I came to feel that it was not well suited for what I wanted to do. As I used it more extensively, I found that the data structure of a wiki was not flexible enough when I want to reuse some part of a page in different context.
Another drawback of a wiki, for me, is that it encourages you to organize your knowledge in a top-down manner, that is, you have to select a main theme as a starting point. But I wanted to write down anything I thought could be useful and organize afterward, as needed.
So I decided to create a software program to meet my needs. The first concept was that users can input finer grained units of information (which I call “knowledge fragments”) and organize them more freely and flexibly. Also, since knowledge fragments can be classified using tags, I thought it would lead to a more powerful tool for knowledge management while retaining the simplicity of a wiki or other notebook applications.
But as I experimented with Piggydb’s knowledge creation, I found out that it did not work as well as expected. I thought originally some sort of structure would gradually emerge in the continuous organization of knowledge fragments with tags. But there’s something missing still in Piggydb to achieve this goal.
What is the missing part? I will try to illustrate this below by comparing two well-known knowledge representation techniques, “Mind Maps” and “Concept Maps”. Concept maps, which I happened to find about recently, are similar to the Piggydb concepts. The contrast between these techniques helps to understand the aim of Piggydb.
The principal difference between these techniques is the structure of their knowledge models. A mind map is a tree which has a central governing concept at its root, while a concept map is a network of concepts. Why is mind mapping far more popular than concept mapping? One of the reasons would be the simplicity of tree structure, which you can create quickly and afterward follow and comprehend easily. A mind map also helps you focus on a single topic during the organization of your knowledge. The combination of this strength of trees and visual images promotes human understanding dramatically, and it is why mind mapping is so popular as a tool to understand or memorize whatever you want to, in a short time.
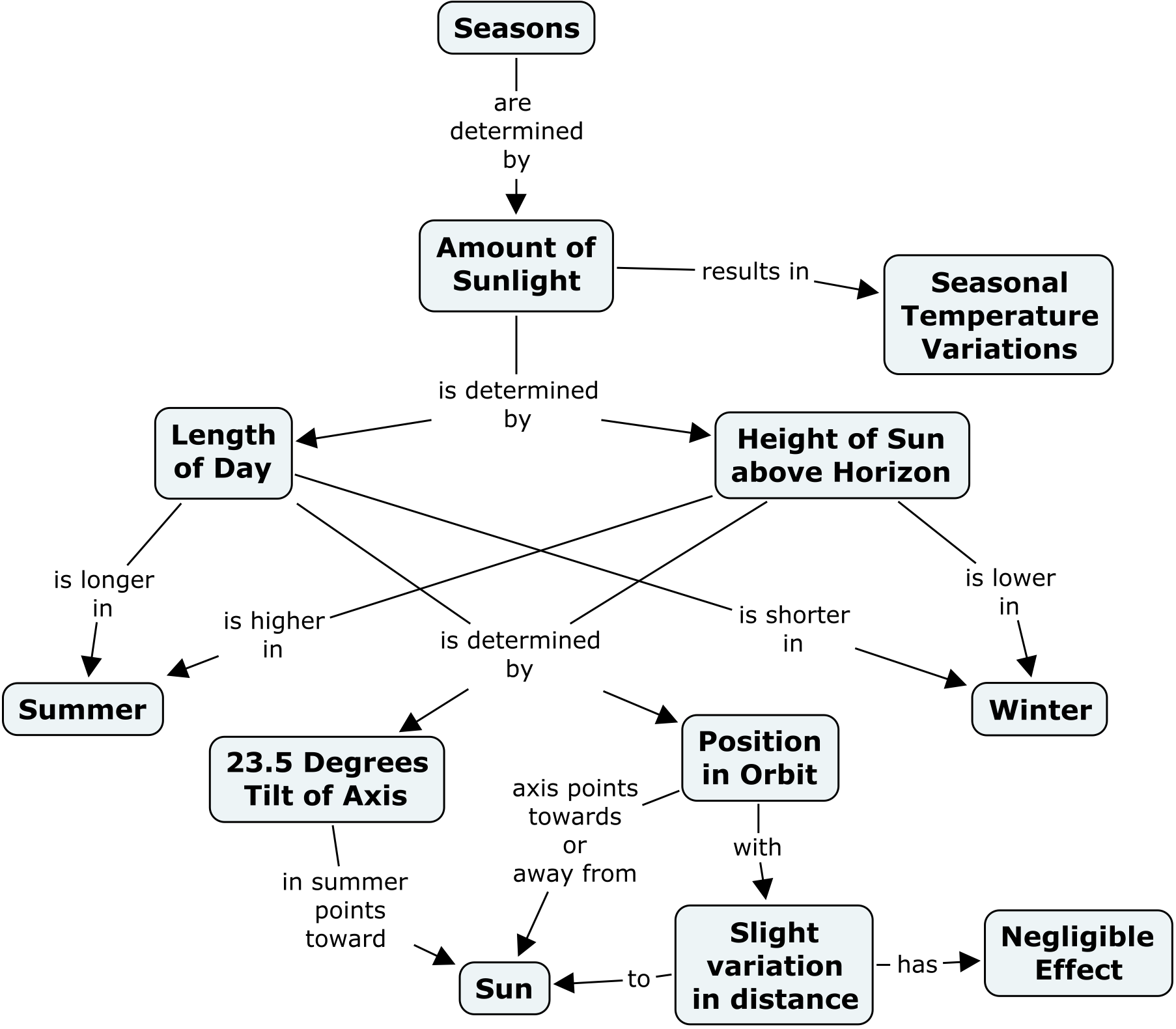
On the other hand, concept maps are not as simple as mind maps and more difficult to create, but still easy to understand and intuitive to read. The strength of concept maps is their expressiveness which allows you to explain more complex relations (see the interesting example from the above site, it explains why we have seasons).
Piggydb adopts a network structure to represent knowledge as concept maps because a network is more capable of managing a large number of interrelated topics, so it is more suitable for a database-like system than a tree structure. Moreover, a network is more flexible and allows you to connect between concepts in different fields, which is called “cross-links” in concept mapping. That, in my view, is the key to creativity.
When I first saw concept maps, I thought that is where Piggydb’s knowledge creation process should lead. This process would start with collecting concrete materials, gradually evolve an abstract structure from them, and then, finally, produce a concept map-like conceptual knowledge map. But there is a part missing to realize this process, and as I wrote above, filling this gap will be the main theme of version 5.x.
One of the flaws of the current Piggydb is that when a user classifies fragments they tend to select categories they already know, which is the opposite of the aim of Piggydb: creating/finding new concepts. This is partly because the Piggydb’s tag system doesn’t much differ from the existing Web 2.0 tag systems and users tend to use it in a way they have already learned. In terms of the data models, tags should have been designed as a specific form of a fragment so that a user can create concepts from existing fragments and tags, and organize them in the same way.
You can use Piggydb as a wiki-like content management system or an Evernote-like database system, and I myself actually use it so in some cases, for example, Piggydb.jp. But as you already know, the goal of Piggydb is a little different from these systems. Although this goal is not fully achieved yet, I’m developing it to be a platform that encourages you to (re-)organize your knowledge continuously to discover new ideas or concepts, and, hopefully, to enrich your creativity.
Next: The Piggydb Way: #1 Tag as Concept over Tag as Index
Piggydb V4.14 released
Posted: September 8, 2010 Filed under: uncategorized Leave a commentThis release adds a sorting feature to the fragments view:

The calendar interface was updated to allow users to select a month as well as a day:

Download Piggydb V4.14 from https://piggydb.net/


{kind=link}
Recent Comments