
The PPCP (Post/Pin/Connect/Promote) Cycle in Cotoami
Posted: September 6, 2025 Filed under: uncategorized Leave a commentI’ve written a Getting Started guide for Cotoami, walking you step by step from installation to the basics of how to use it. The guide also introduces Cotoami’s proposed method for knowledge creation, the PPCP (Post/Pin/Connect/Promote) Cycle, explained with real examples. This method represents one of the conclusions I’ve reached about how to cultivate a knowledge base, an exploration that goes back to the Piggydb days.
Getting Started with Cotoami, a Personal Knowledge Base for Discovery
Introducing the New Masonry Layout for Stocks in Cotoami
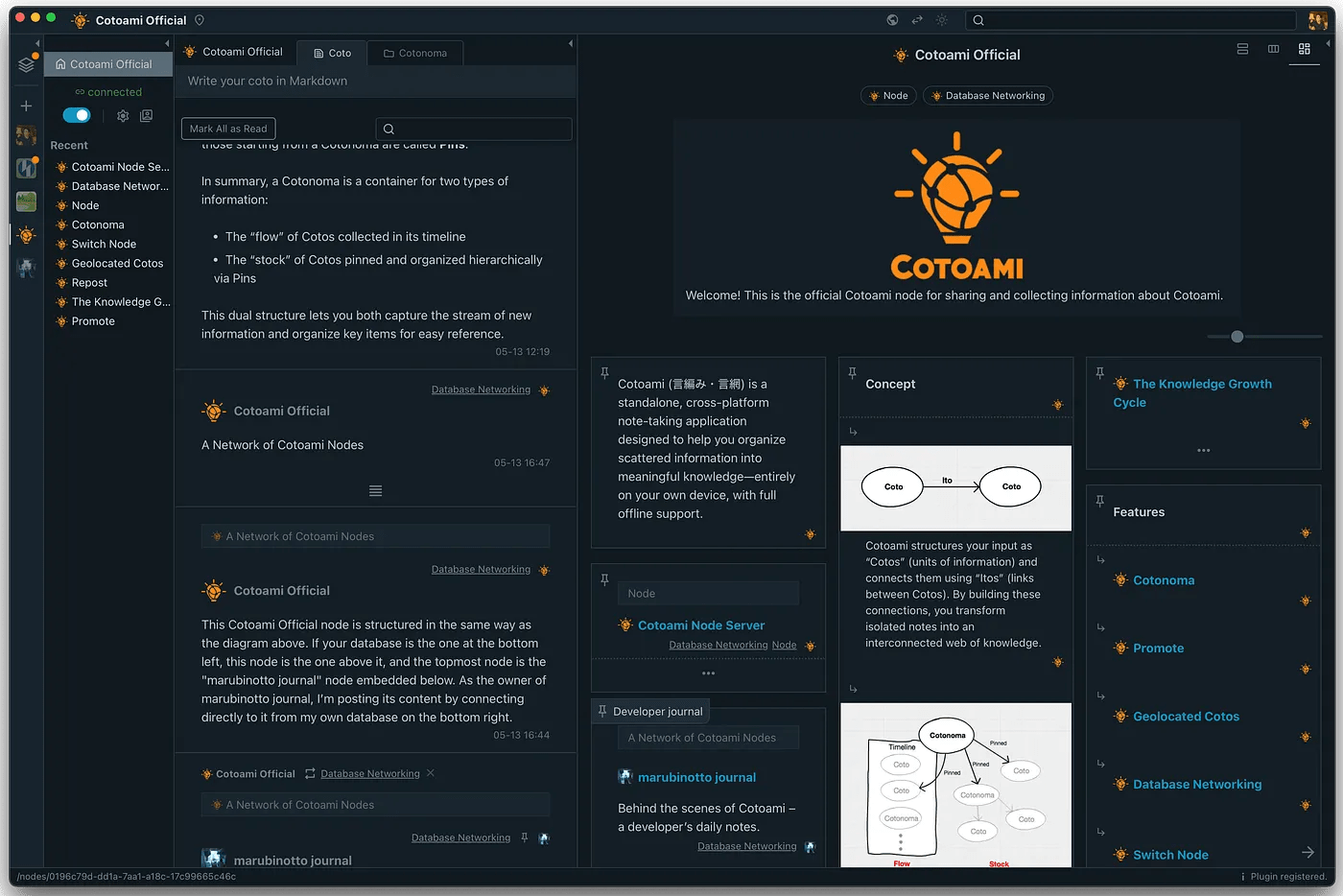
Posted: August 22, 2025 Filed under: uncategorized | Tags: knowledge-management, open-source, technology Leave a commentCotoami offers two main ways to view your input: Flow and Stock. In the screenshot below, the left side shows the Flow timeline, while the right side displays pinned items in the Stock.
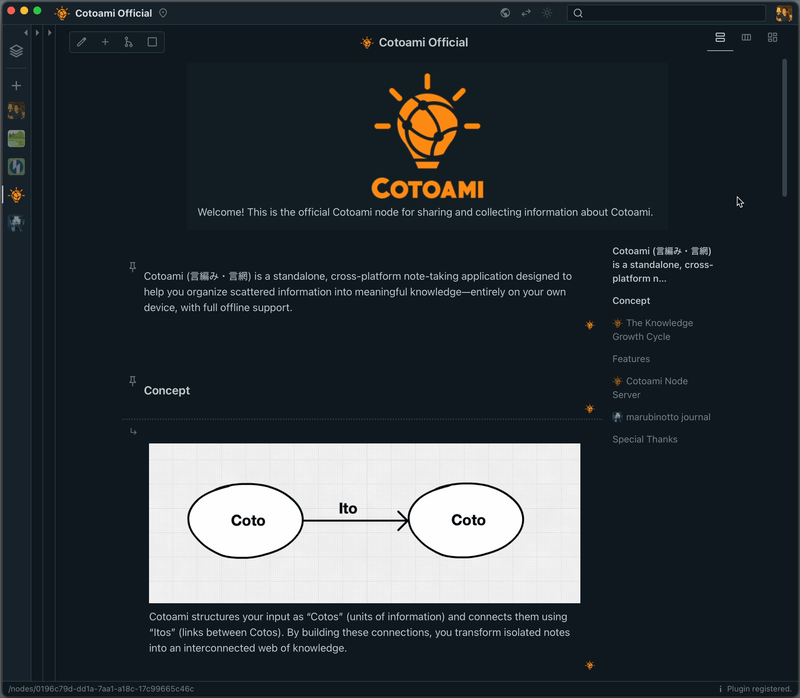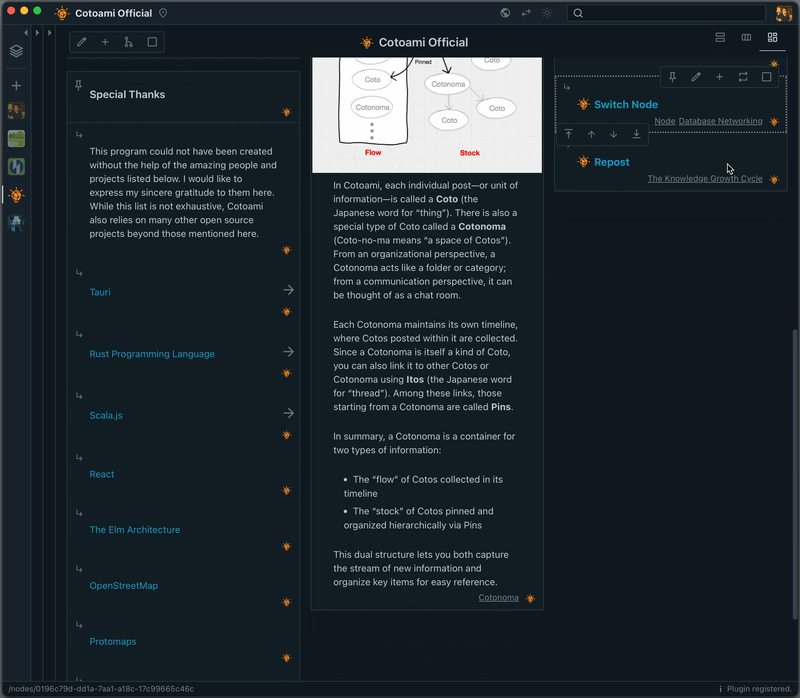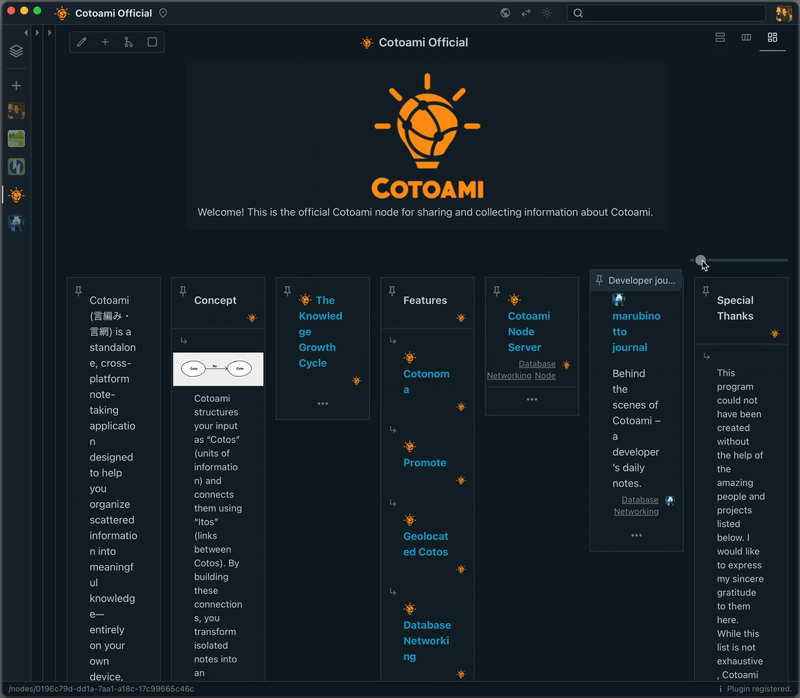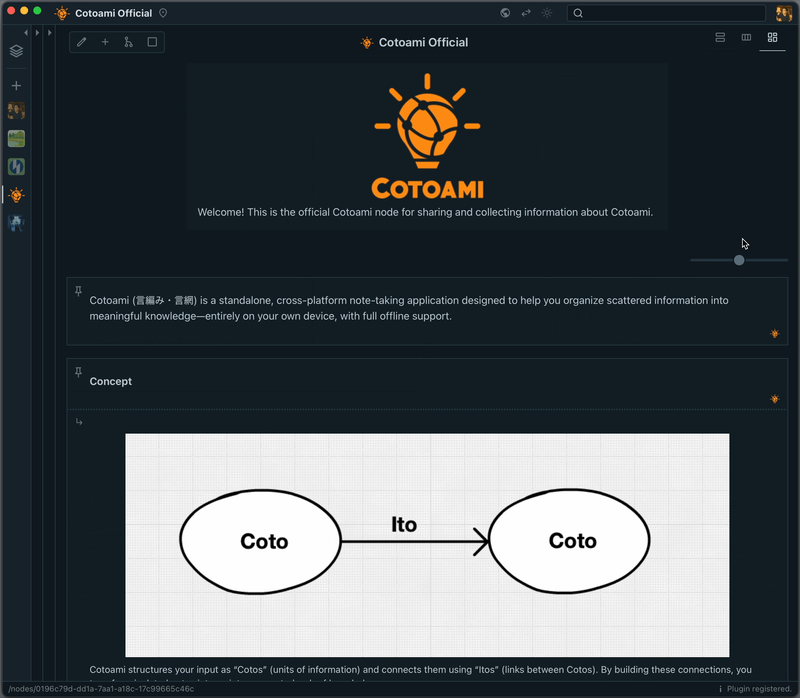
Flow is an unstructured stream of posts arranged in chronological order, where you can casually throw in any information without hesitation. From there, you can pin items that matter to you and collect them in the Stock on the right, gradually building a structured knowledge base. This is the basic way to use Cotoami.
Until now, Cotoami has provided two layouts for viewing Stocks: Document and Columns.
In the screenshot above, the Stock is shown in Document layout, with a table of contents on the right. This makes it easy to “read” the information as a standard document, which works especially well when you have a Stock with a lot of text.
With Columns, information is displayed side by side, as shown below. This layout is particularly effective for Stocks that include many lists, such as TODO lists. Personally, I often use it like a kanban board.

In the latest version of Cotoami, I’ve added a new layout: Masonry. This layout arranges individual items in a compact, tiled style, making it easy to take in the big picture of your Stock at a glance. You can also adjust the element size with a slider.
The masonry layout is especially useful when working with Stocks that contain a lot of images, as shown below.
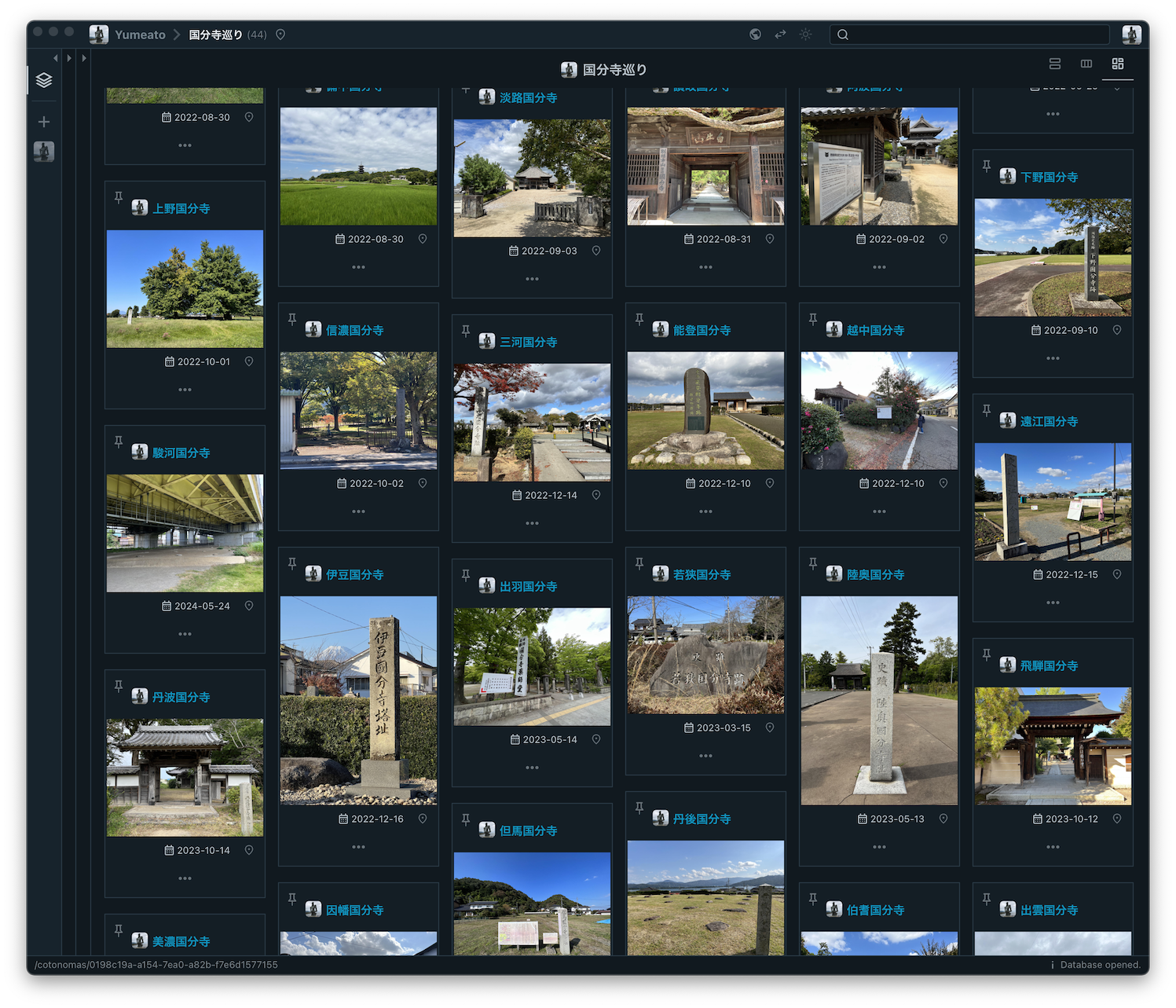
What do you think of this new feature? Since I use Cotoami to plan and record my travels, this addition has become personally very important to me.
If you haven’t tried Cotoami yet, please download it from the release page below and give it a try. Installation packages are available for macOS, Linux, and Windows. And I’d love to hear your feedback!
https://github.com/cotoami/cotoami-remake/releases/tag/desktop-v0.10.0
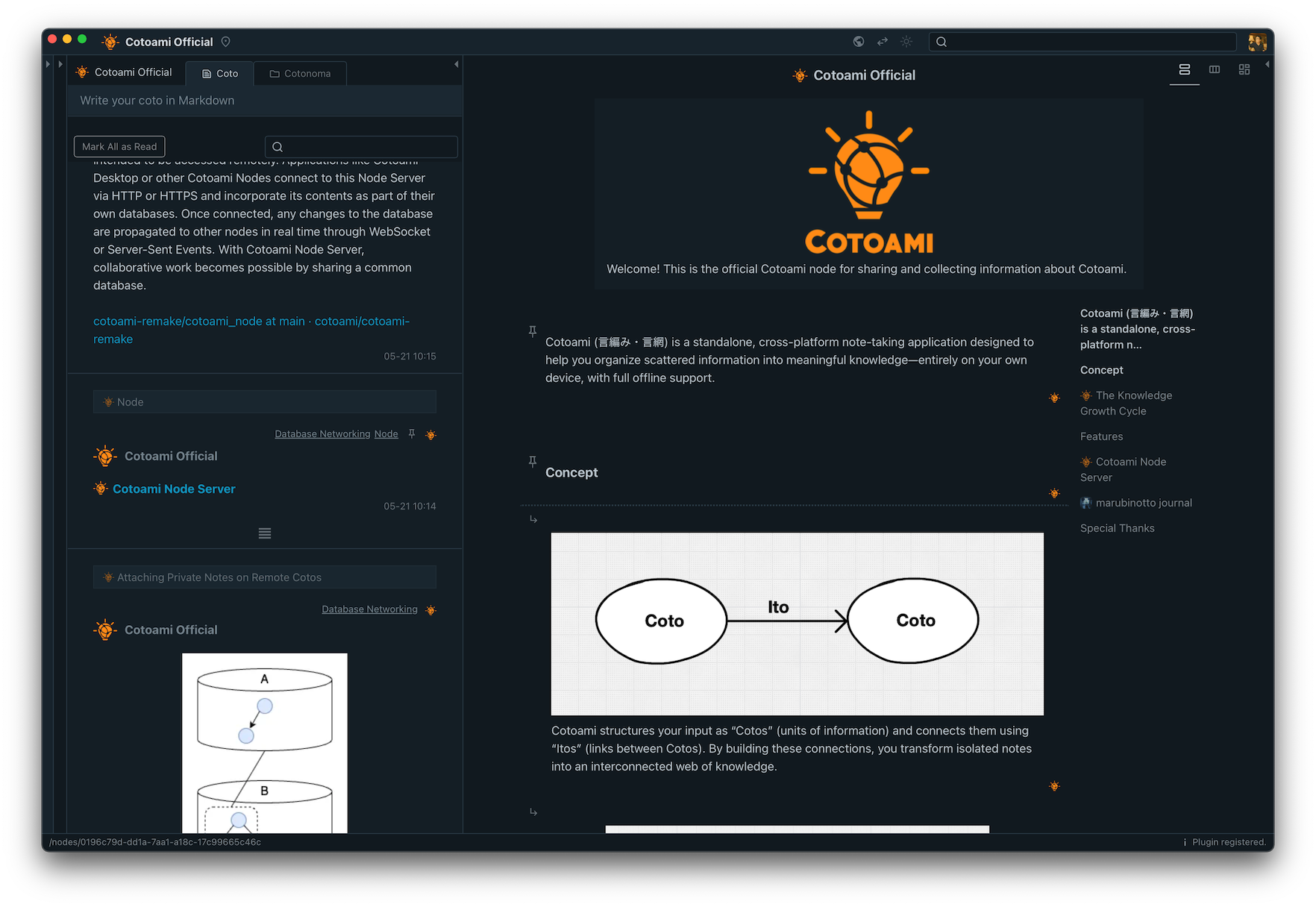
Cotoami as a Knowledge-Centric ChatGPT Client
Posted: July 9, 2025 Filed under: uncategorized | Tags: ai, artificial-intelligence, ChatGPT, knowledge-management, LLM, open-source, technology Leave a commentHello everyone! Today, I’d like to introduce a new feature in Cotoami: the ChatGPT plugin.
If I had to name one major difference between Cotoami and Piggydb, it would be the adoption of a chat-like interface to lower the barrier to input. The idea is that even a quick, one-line note—or information that might turn out to be completely useless later—can be entered without hesitation.
On top of that, Cotoami allows you to connect databases with each other, forming a network. This means that when you’re working on a shared database, registering information into a knowledge base essentially becomes a chat. And when it feels like a conversation, the psychological hurdle of writing things down drops even further. This is the underlying philosophy of Cotoami: start small and grow over time, or distinguish between “flow” and “stock.”
I’ve long thought that this kind of system would work well with an AI chatbot. But since Cotoami is fundamentally designed to be a standalone, privacy-friendly application that works offline, I hadn’t planned to include such functionality by default. However, once the core features of Cotoami were in place, I began experimenting with an extension mechanism using WebAssembly. As the first official plugin using this system, I’m happy to introduce the ChatGPT plugin.
Cotoami Desktop v0.8.0 Release Notes
This plugin makes full use of Cotoami’s unique features to provide some really powerful capabilities. If you’re curious, I encourage you to give it a try.
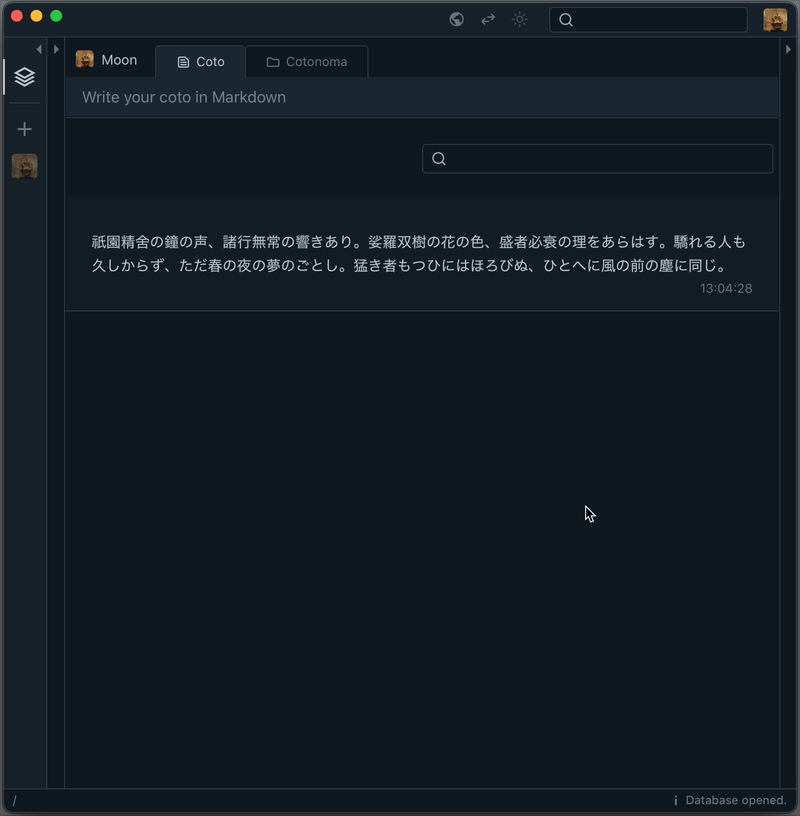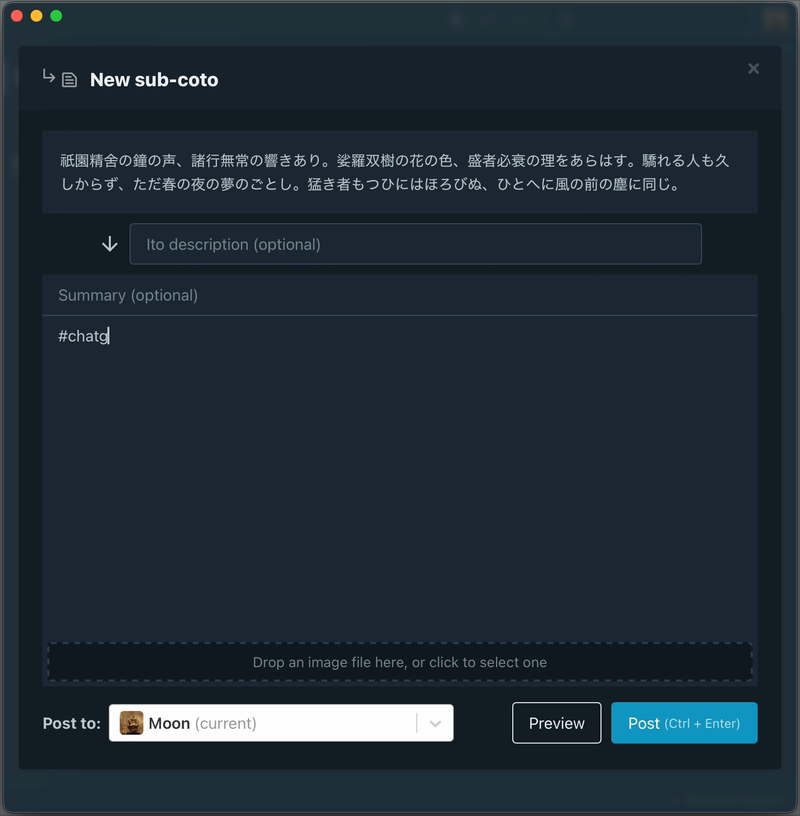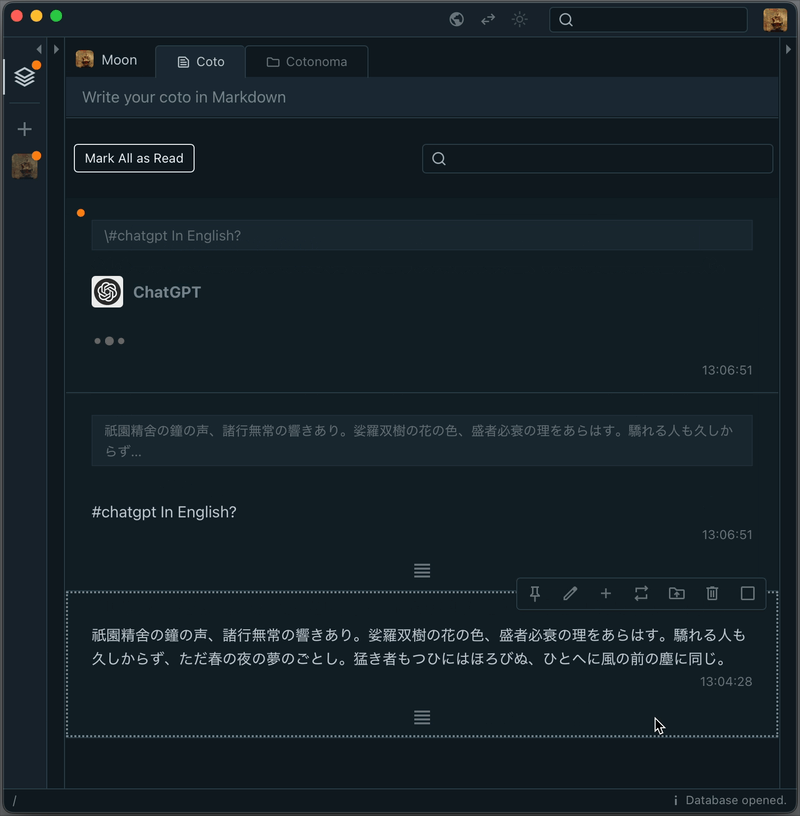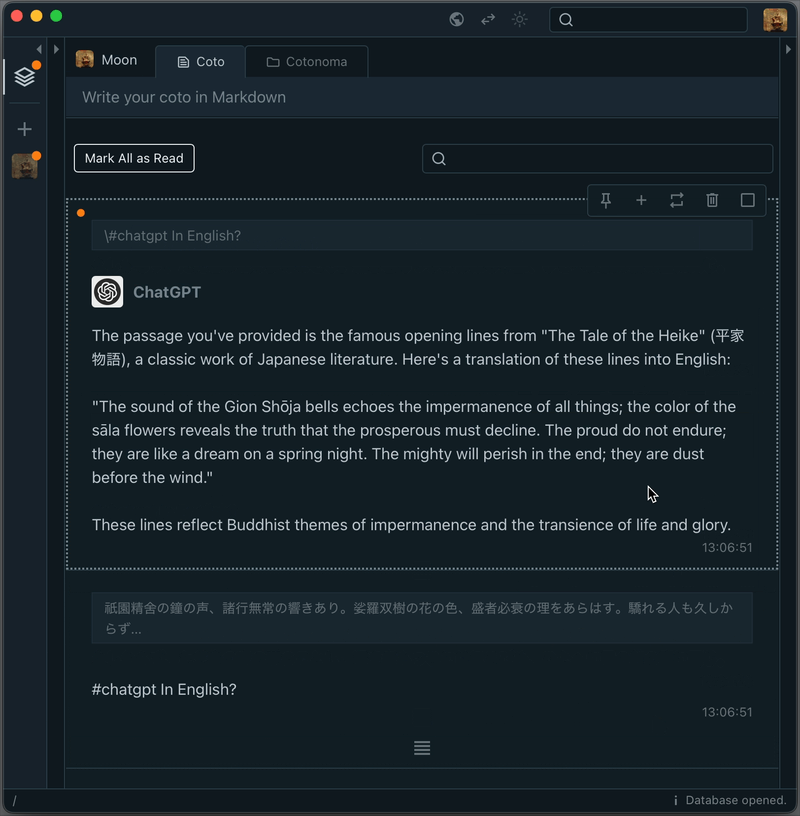
Here’s how it works at a basic level: if you post a note that starts with #chatgpt, it will trigger a response from the ChatGPT API.
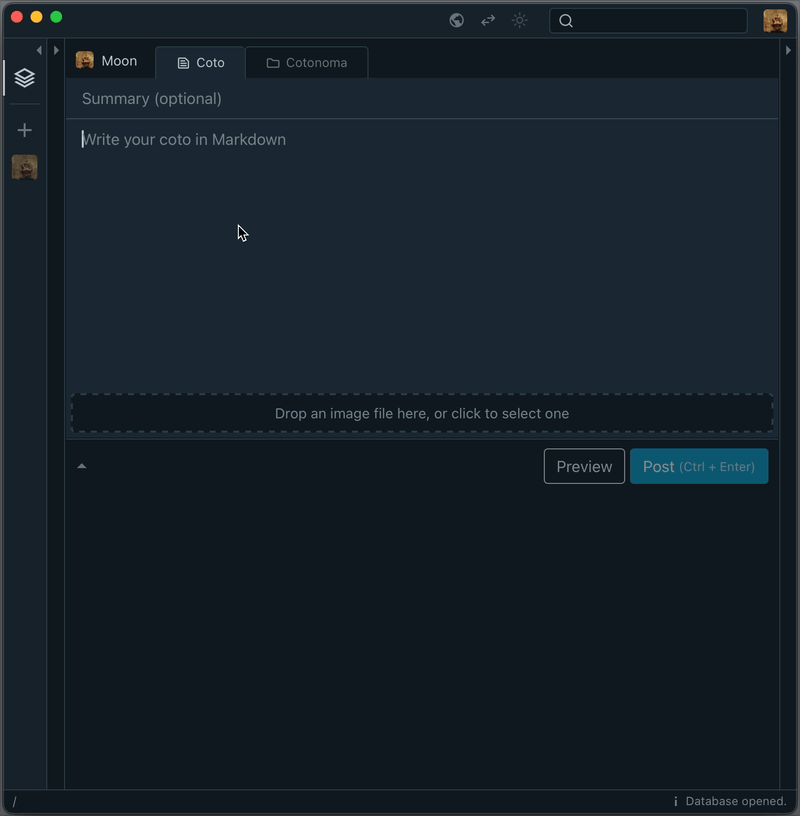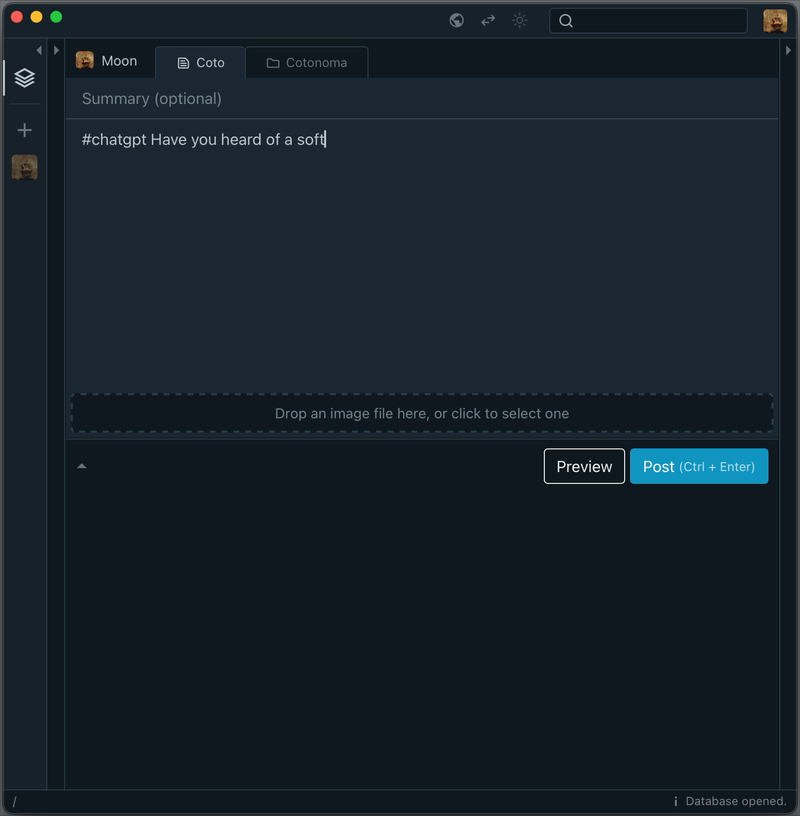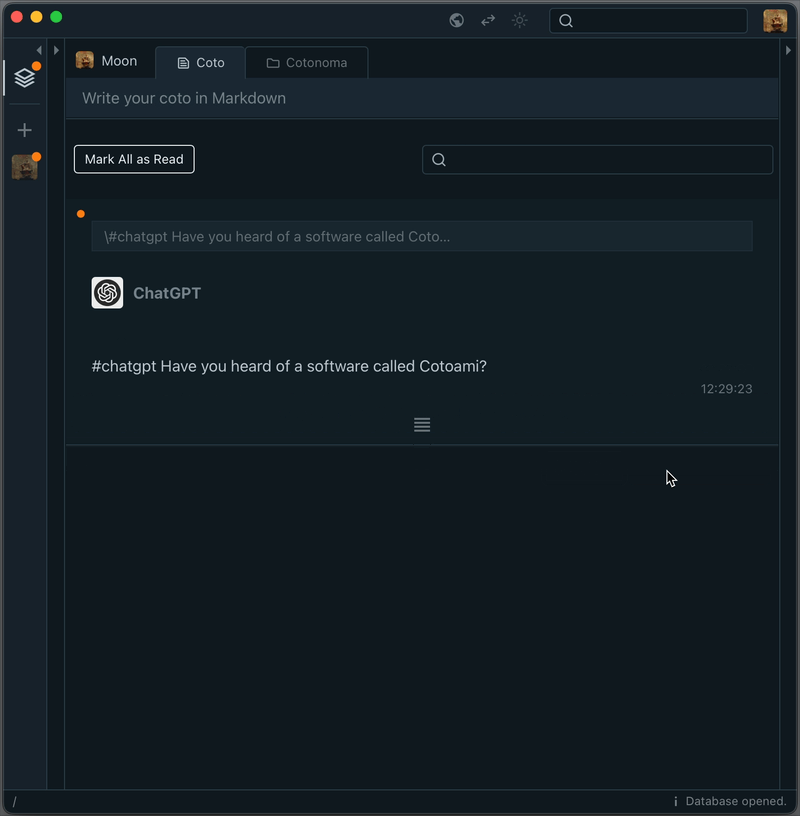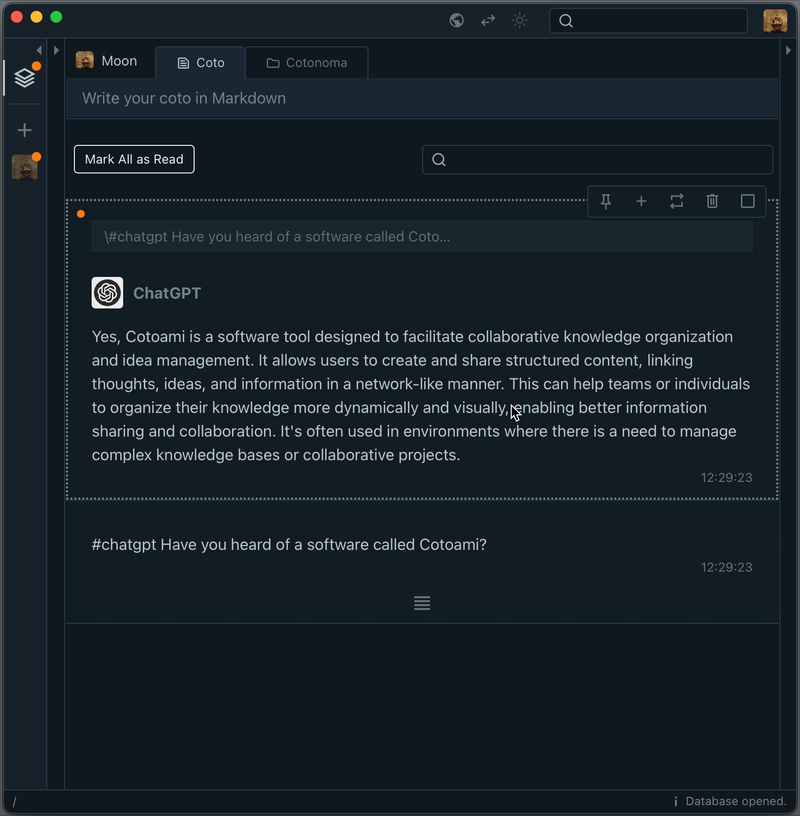
The response is saved in your Cotoami database, which means you can treat it as part of your growing knowledge graph. You can pin important replies or embed them into larger documents.
But simply asking one-off questions doesn’t bring out the full potential of large language models. That’s why Cotoami lets you pass your previously accumulated knowledge graph as contextual information to the ChatGPT plugin. This is the first unique feature of Cotoami’s integration.
Because you can freely edit your knowledge graph, you’re able to prepare and customize the context before sending it to the LLM—by combining multiple threads, trimming away irrelevant parts, and so on.
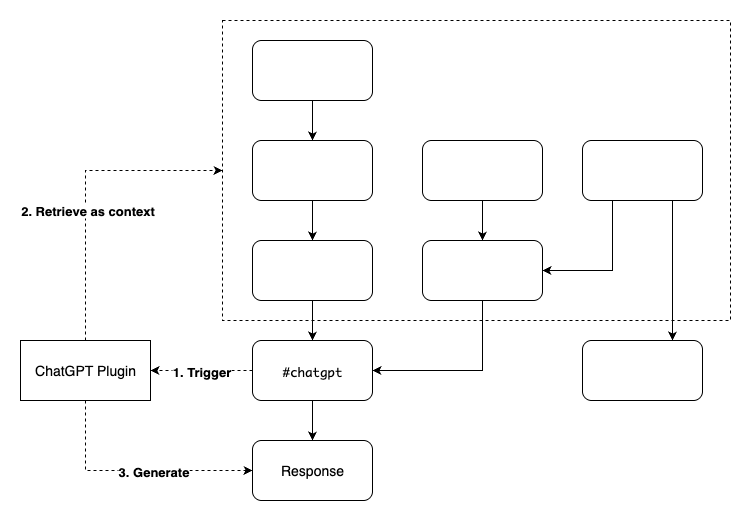
The second unique feature is that the ChatGPT plugin can recognize the authors of each Coto included in the context. This allows it to answer questions about who said what. It’s particularly useful in situations that involve group discussions.
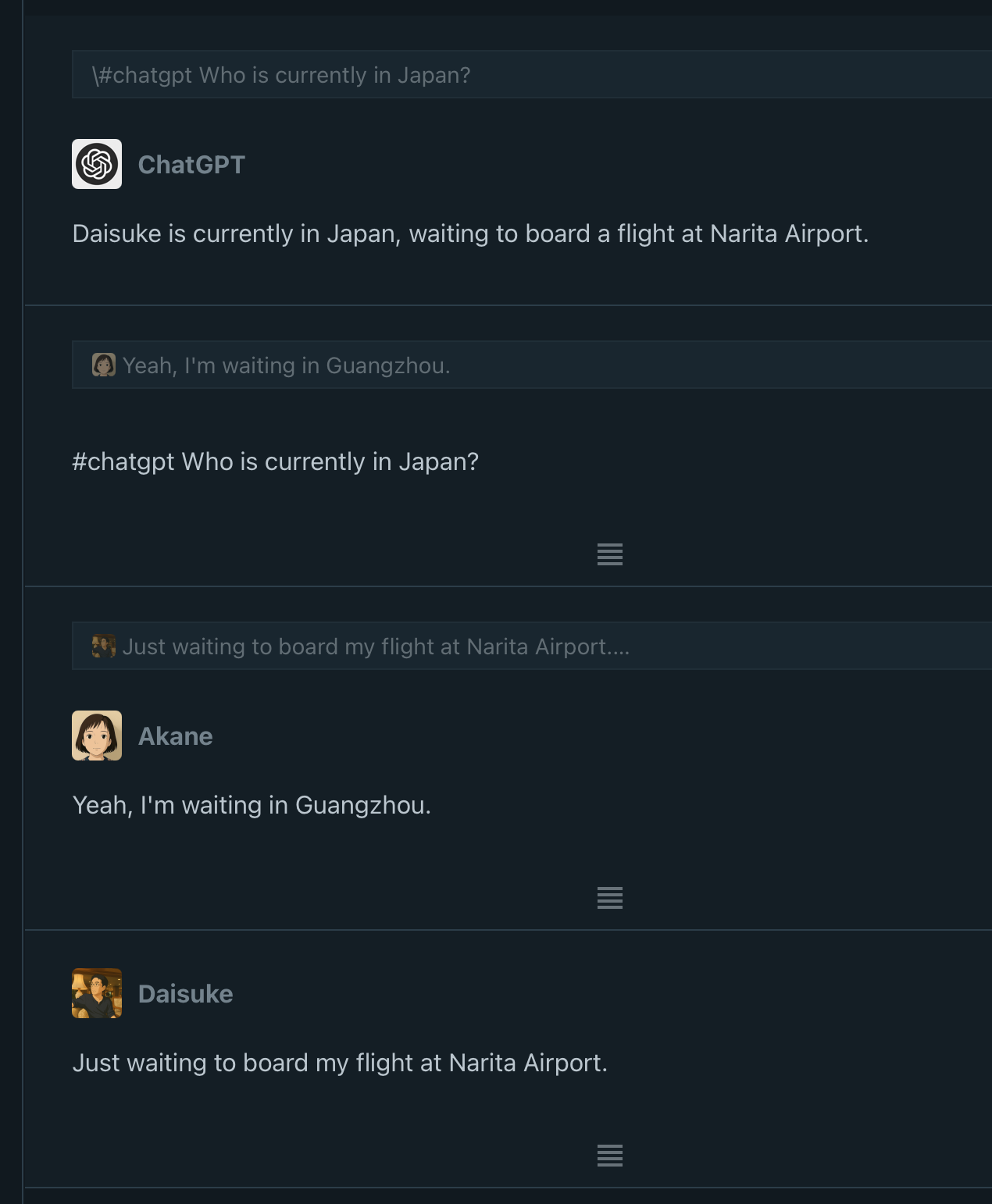
That’s the overview of the new ChatGPT plugin. What do you think? If there’s enough interest, I might create plugins for other LLMs as well. I’d love to hear your feedback!
Hello everyone, long time no see.
Posted: May 27, 2025 Filed under: uncategorized | Tags: blog, blogging, knowledge-management, life, open-source, personal, software, travel, writing 4 CommentsI have no idea how many people still visit this site, but I hope you’re all doing well. It’s been over five years since my last post here—and seven years since Piggydb’s 10th anniversary. Today, I’m writing this simply as a way of saying: I’m still alive, and yes, I’m still doing the same kind of thing.
It’s hard to believe, but it’s been nearly 20 years since I first released Piggydb. If you happened to know about it even before 2010 and are reading this now, I’d honestly want to give you the biggest hug—that’s how long it’s been.
As I mentioned in my previous post, after ending development on Piggydb, I went on to create its successor: a piece of software called Cotoami. More than five years have passed since then, and development on Cotoami has also been on hold for a while. But personally, I’ve continued to use it—both for work and for my own life. One of my original goals was to build something I could keep using myself, and in that sense, I achieved that goal.
Still, as I kept using it, new ideas began to emerge. Eventually, I felt a strong urge to rebuild it from the ground up. One thing that bothered me was how Cotoami, unlike Piggydb, wasn’t something you could easily try out in a personal environment.
I knew full well how difficult it would be to rebuild a piece of software that took years to create. But I also felt this might be my last chance to do something like this, so I decided to throw in everything I wanted to do. And after about two and a half years of work, I’ve finally finished it. It’s called Cotoami Remake.
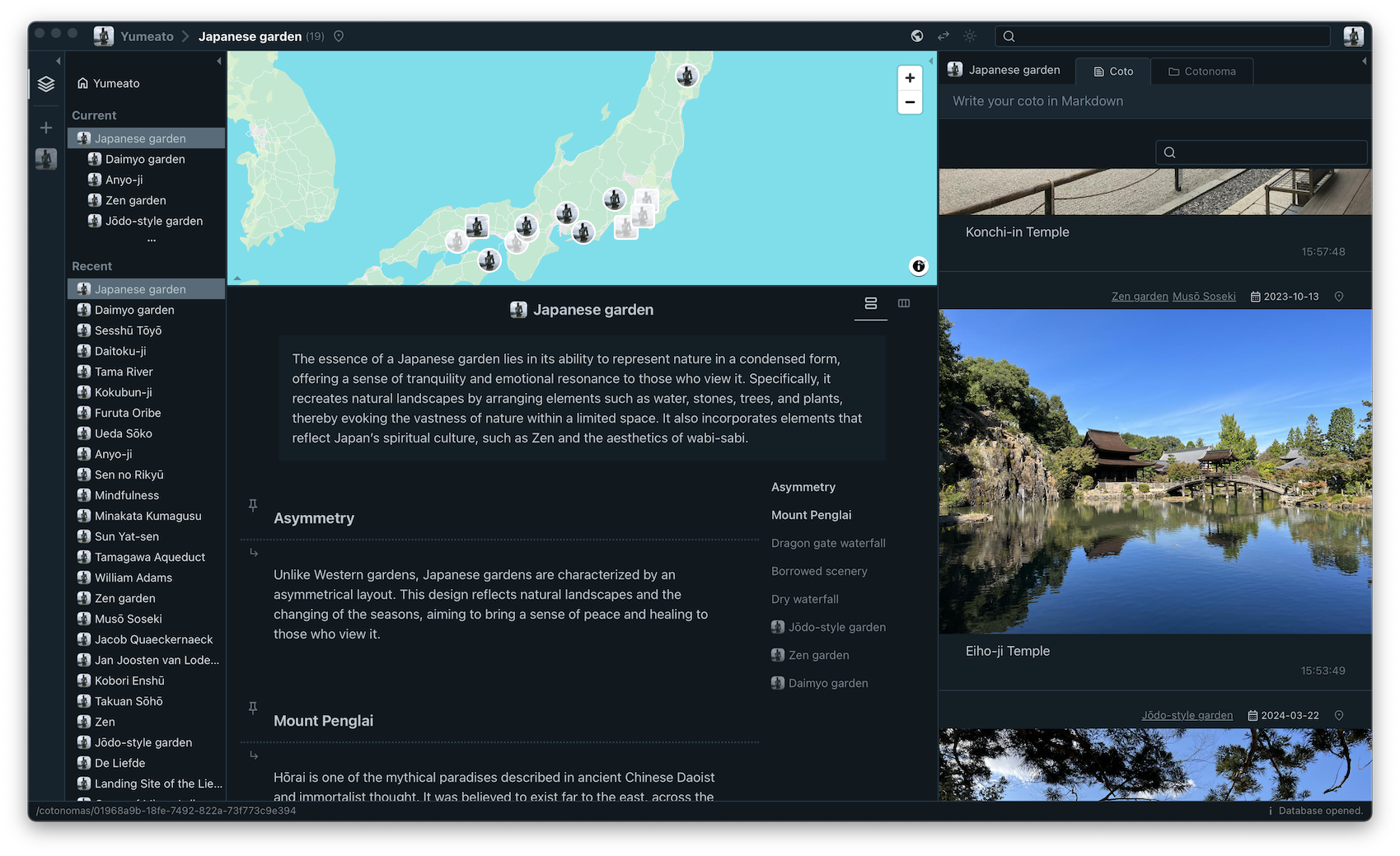
This software is the culmination of 17 years of experience. It might very well be the last thing I build on this scale as a solo project—or at least, I built it with that mindset. If you’ve ever used Piggydb, or were curious about it in the past, I’d love to know what you think. These days, there are countless note-taking tools and apps available, and most people’s needs are probably already met. So I don’t expect many to pick up a personal project like this. But if you’re even a little bit curious, I’d be thrilled if you visited the project site, gave the app a quick try, and shared your thoughts.
I honestly don’t know why I’ve spent nearly 20 years making things like this. With Cotoami Remake, I feel like I’ve finally found closure. It might be the last new software I ever make. Going forward, I plan to share travel journals inspired by the core concept of this software. I don’t know how many people will be interested in that, but I think it’s a fascinating project that transforms the idea of “discovering knowledge” into “discovering destinations.”
A Journey Through Names — Stop 1: Hamura Intake Weir — A River, a Name, a Beginning
If you’re someone who just happened to visit this site again after a long time, I’d be really happy if you left a quick comment—even just to say hi.
Take care, everyone.
Why it’s harder to discover valuable knowledge in tree-structured note-taking
Posted: March 6, 2019 Filed under: uncategorized Leave a commentRecently, Cotoami project, the successor of Piggydb, released a new feature called “Linking Phrases”.
As you can see in the screenshot below, it allows annotating a connection when you feel a need for some explanation of it.
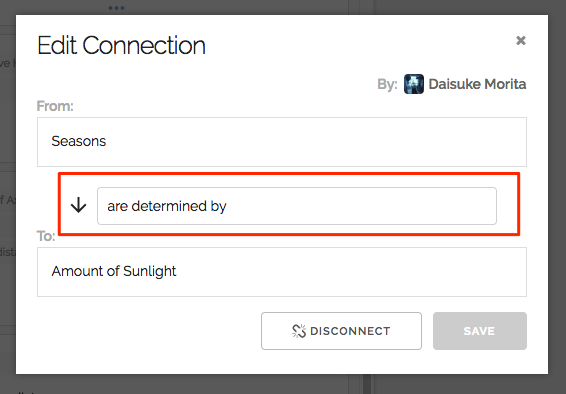
I thought about this enhancement when I was working on Piggydb some years ago but suspected it would just complicate things without adding much value. Piggydb aimed at becoming a simple note-taking tool, not a modeling tool. After all, you can express a labeled relationship by adding a node between the two.
However, I came up with an idea of “Horizontal and Vertical Relationships” recently and thought it would become one of the significant features in Cotoami.
The term “Linking Phrases” is borrowed from Concept Maps, which I mentioned in the article Wiki, Mind maps, Concept maps, and Piggydb before.
When I first saw concept maps, I thought that is where Piggydb’s knowledge creation process should lead.
Since it focused on the structure or knowledge-creation-process side of Concept Maps, Piggydb hasn’t had an update to support writing Concept Maps so far, but now, Cotoami supports it as a result of this enhancement.
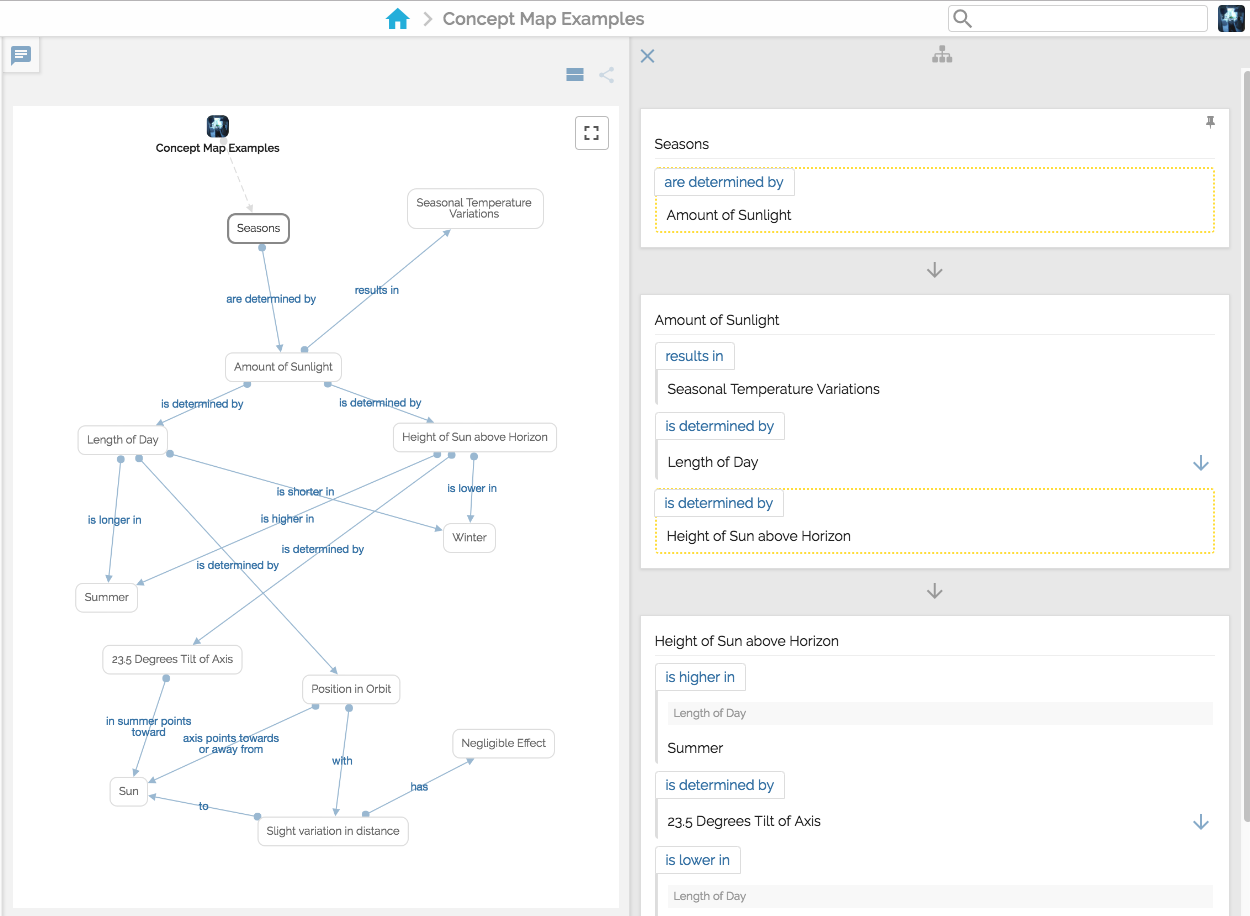
The above concept map explains why we have seasons (the original concept map is presented in the article at Concept Maps official website: http://cmap.ihmc.us/docs/theory-of-concept-maps). If you are interested in how this concept map was created with Cotoami, here is a youtube video to demonstrate the process:
Concept mapping is an excellent way to demonstrate this feature, but a significant difference is that Cotoami’s linking phrases are optional. That means you should avoid annotating connections unless the relationships are obscure to you. Those unclear relationships are possibly valuable knowledge for you (since you didn’t know them well before), and should be highlighted in your knowledge-base. I call them Horizontal Relationships.
On the other hand, Vertical Relationships generally means inclusive or deductive relationships like “has”, “results in”, or “is determined by” appeared in the concept map example above. Most connections would fall into this category. Simple arrow lines would be enough to express these relationships, and you wouldn’t feel the need for annotations in most cases.
Whether a connection is horizontal or vertical depends on you or your group. For example, if you are a table tennis fan, the connection below should be obvious:
[Table tennis] ----> [Jan-Ove Waldner]
But if you are not, there’s a need for some explanation:
[Table tennis] --(legendary player)--> [Jan-Ove Waldner]
In the process of Cotoami’s knowledge creation, horizontal relationships would be a small portion of all connections but represent some important discoveries in your knowledge-base. That’s why I introduced this enhancement. Annotating only horizontal relationships won’t complicate things.
This idea also leads to the insight described by the title of this article. It would be difficult to deal with both horizontal and vertical relationships at the same time in tree structures which mainly deal with the latter.
With this update, Cotonomas (Cotonomatizing), which I explained in the previous entry, and Linking Phrases are the most two essential features so far in Cotoami. Both are for highlighting your discoveries.
If you are interested in Cotoami’s way of note-taking, check out the project website on GitHub (https://github.com/cotoami/cotoami). It would be fairly easy to try it out on your PC.
The project is also waiting for your support by becoming a patron at https://www.patreon.com/cotoami. In return, you’ll get an account of the fully-managed official Cotoami server.
The 10th anniversary of Piggydb and the current status of the journey
Posted: October 7, 2018 Filed under: uncategorized 4 CommentsHello.
Piggydb turned 10 this summer. It was August 27, 2008, when I released the first version.
Recently the project is in a dormant state. It’s been more than two years since the last release (February 2016).
In 2010, I wrote about the goal of Piggydb:
But as I experimented with Piggydb’s knowledge creation, I found out that it did not work as well as expected. I thought originally some sort of structure would gradually emerge in the continuous organization of knowledge fragments with tags. But there’s something missing still in Piggydb to achieve this goal. – Wiki, Mind maps, Concept maps and Piggydb | Piggydb
So what’s the current status of the journey to the goal?
I think I’m almost there.
Piggydb would be powerful in terms of creating highly structured content with fragment relationships and hierarchical tags, but not good at providing a place of generativity as quoted above.
The “Table Tennis Videos” demo site is a good example for this.
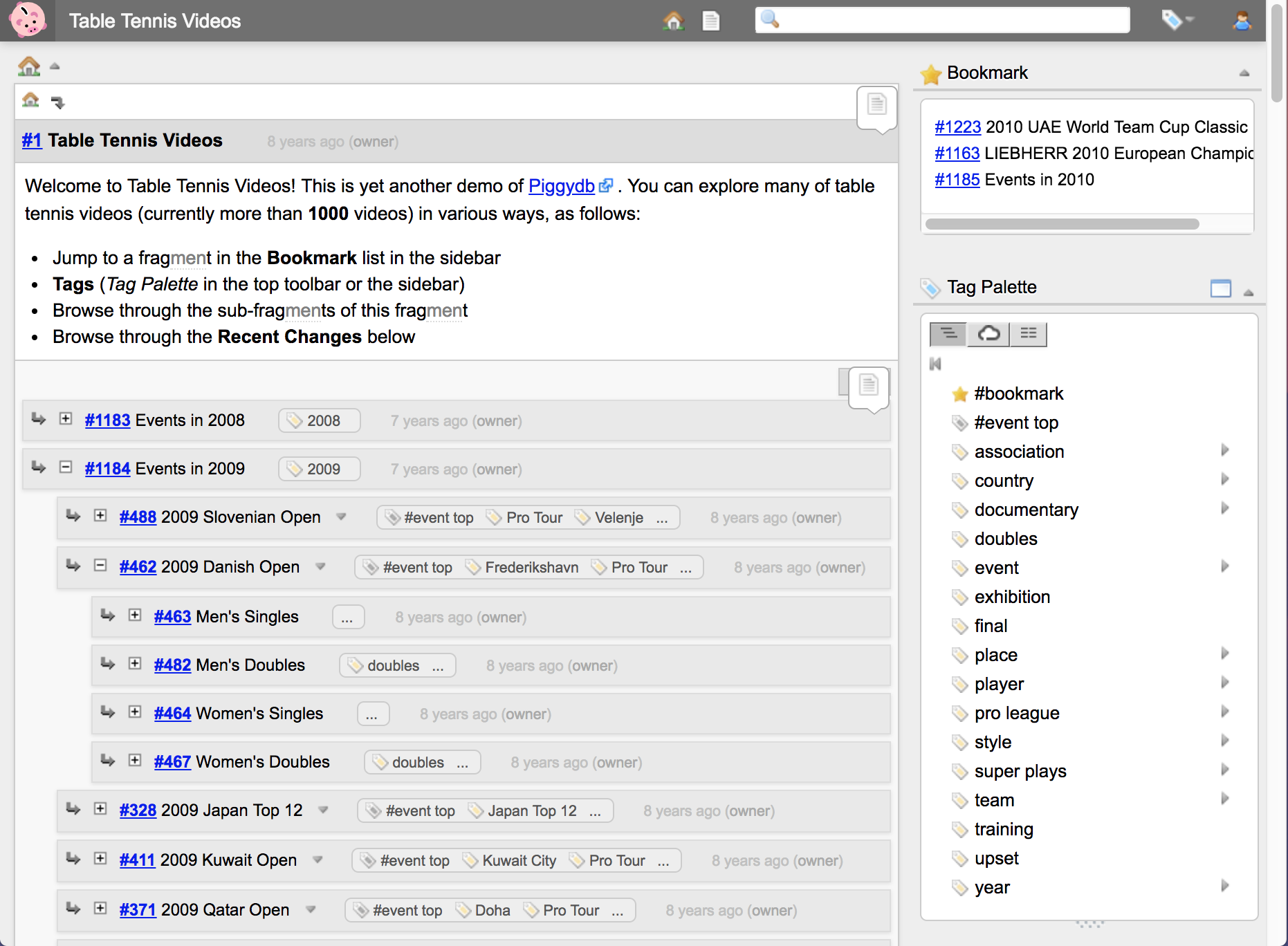
It’s well structured and tagged so that visitors can search the videos in various ways. However, once you decided a system of structure and tags, you can’t escape from it easily. You just input fragments so as to align with the existing structure.
It’s actually useful for certain purposes, especially for displaying some information, but I myself want to escape from static structures. If you use it as a personal or team knowledge base, it wouldn’t last long because it’s highly possible there’s no metabolism occurring in it.
This experience made me rethink the principles needed to realize metabolism in digital note-taking, and that led to the Cotoami project I’m currently working on.
![]()
The first principle implemented in Cotoami was to make the barrier to input as low as possible.
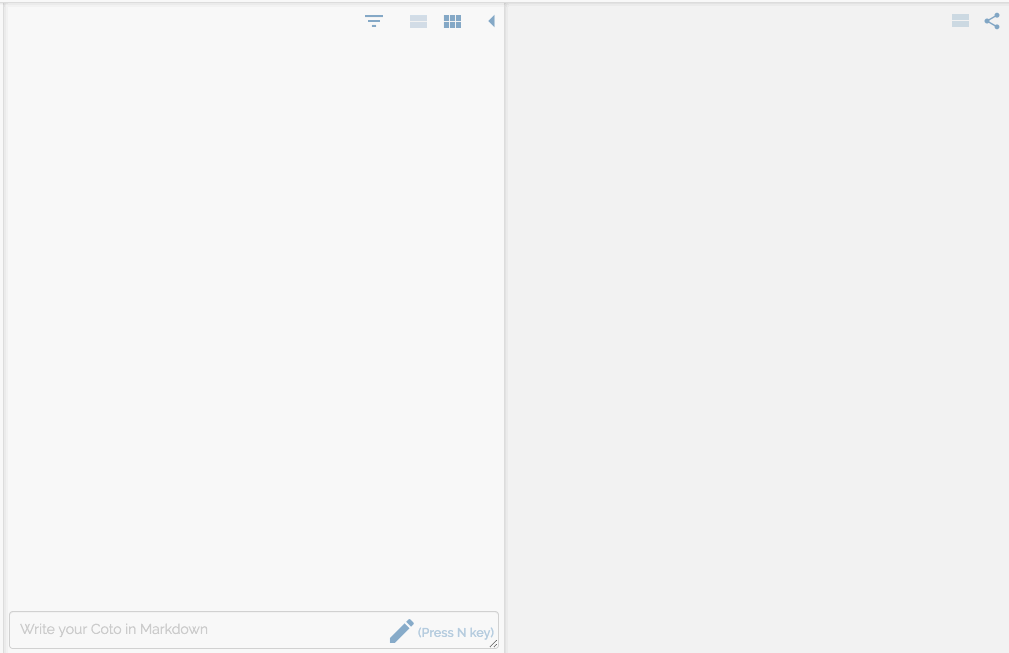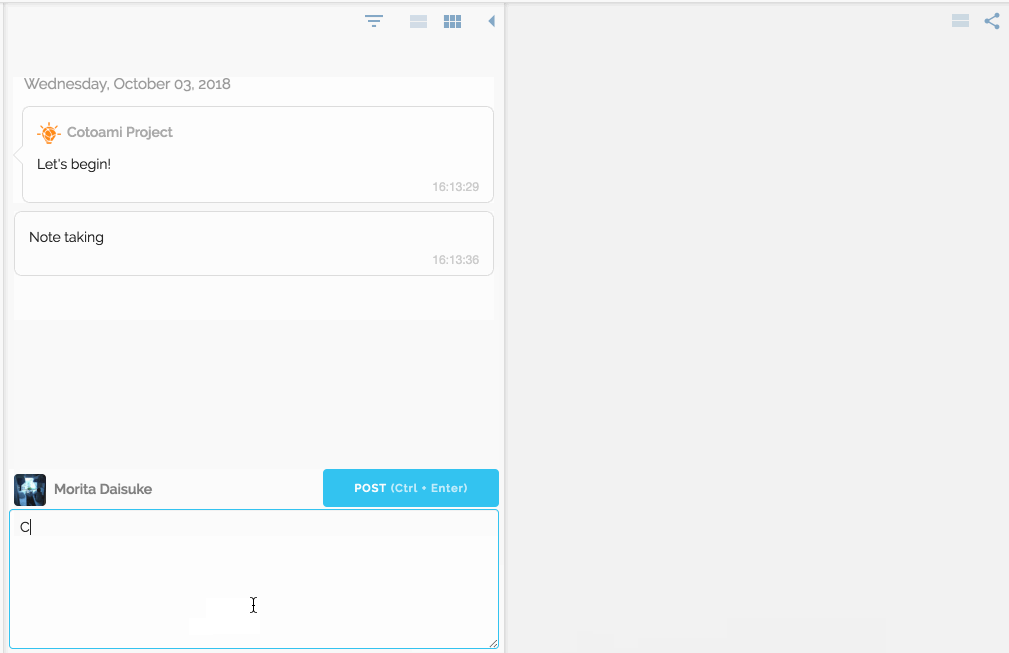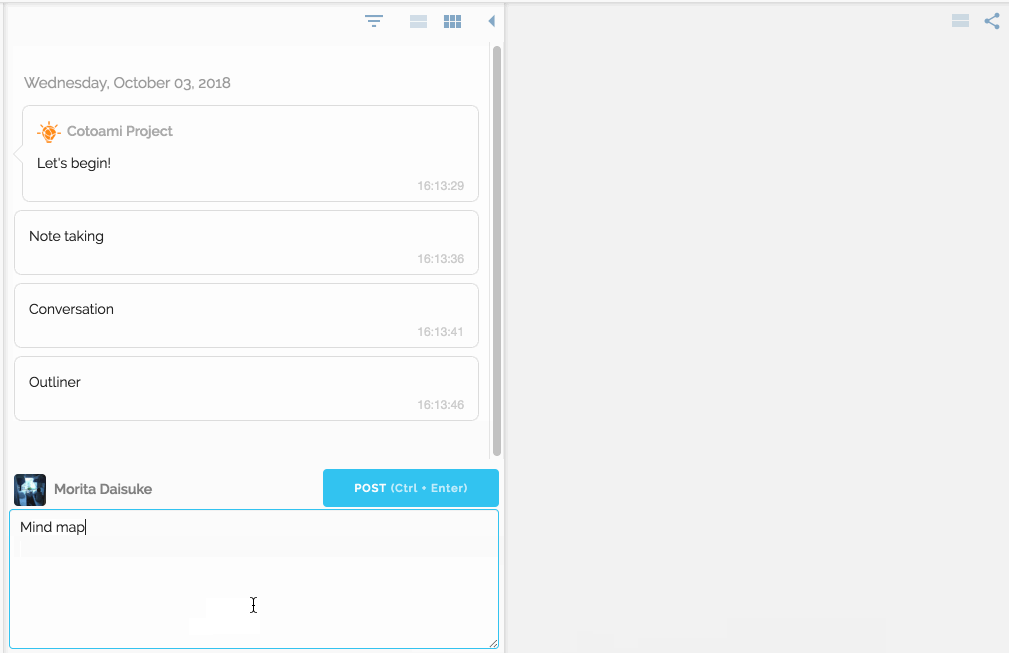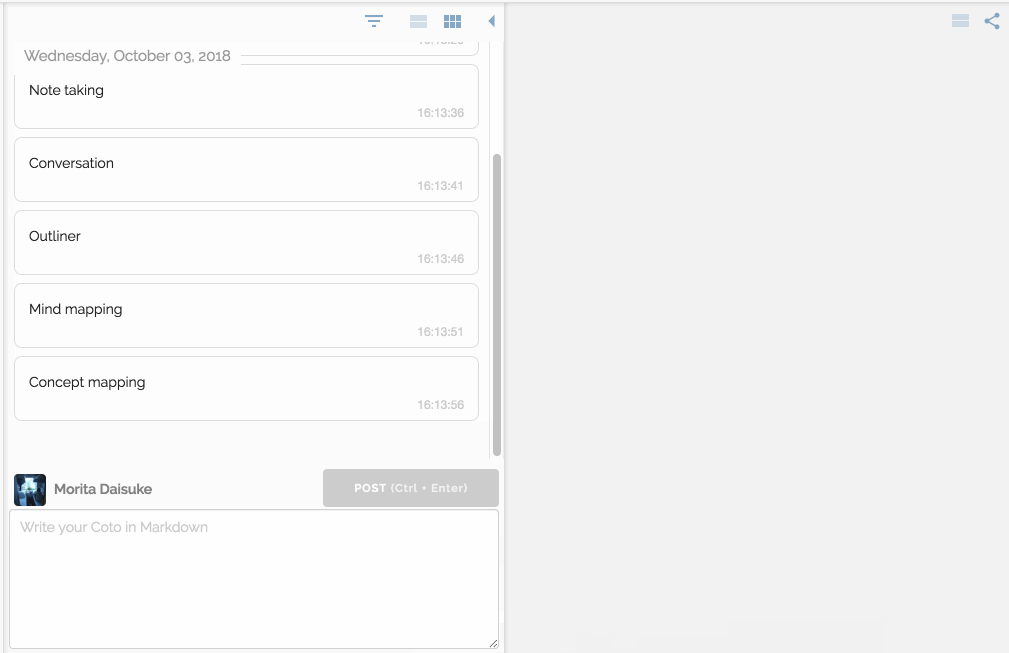
In Cotoami, you post your ideas and thoughts like chatting. It’s actually a chatting feature where you can chat with other users sharing the same space.
You would feel free to write anything that comes in your mind. Your posts just flow into the past unless they are pinned:
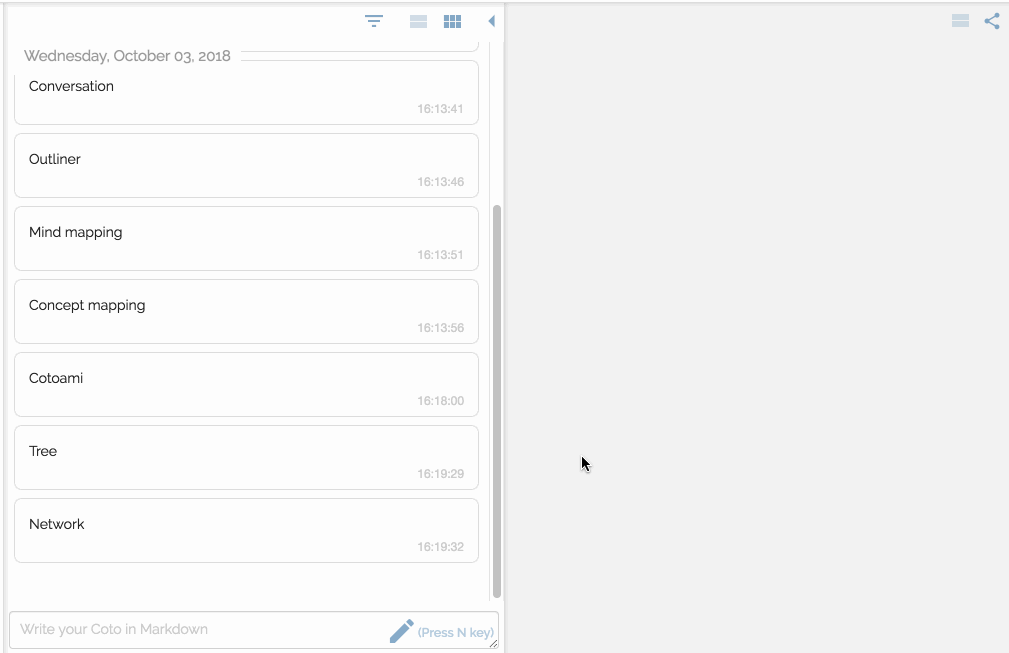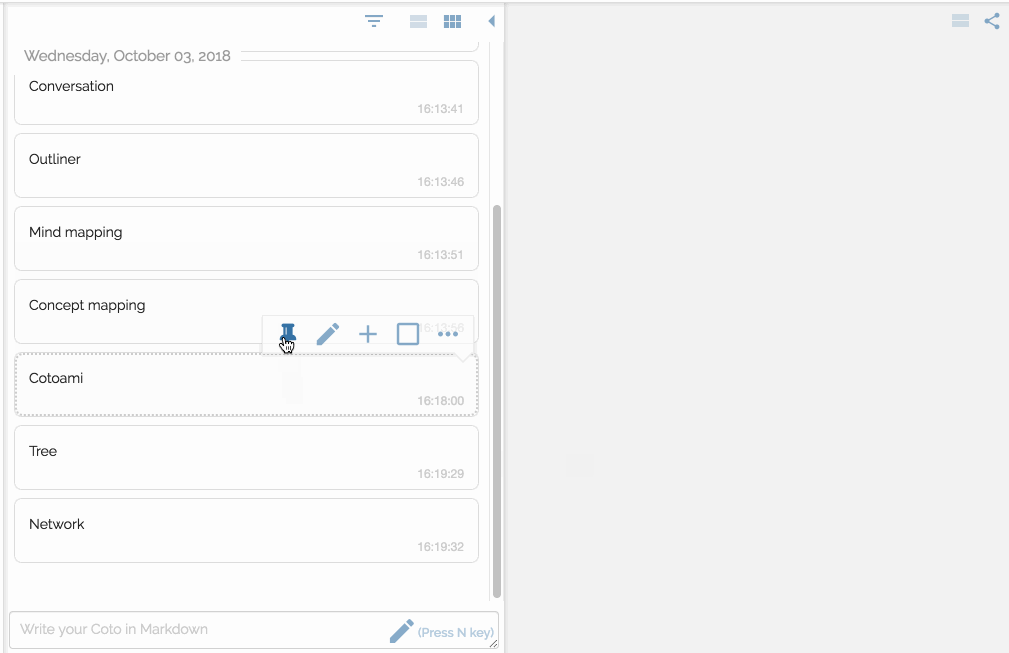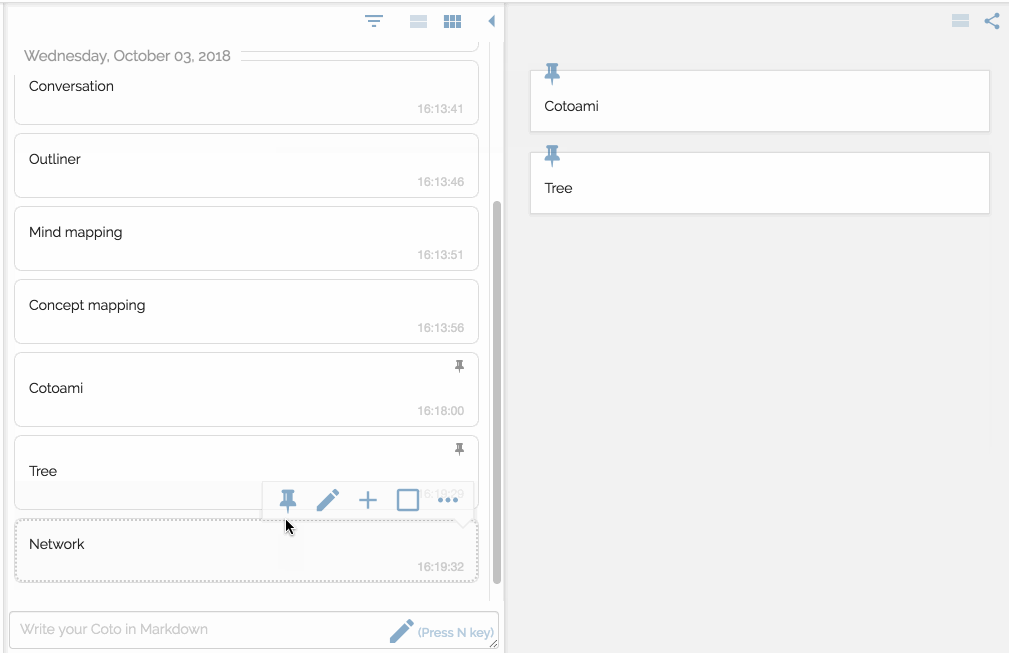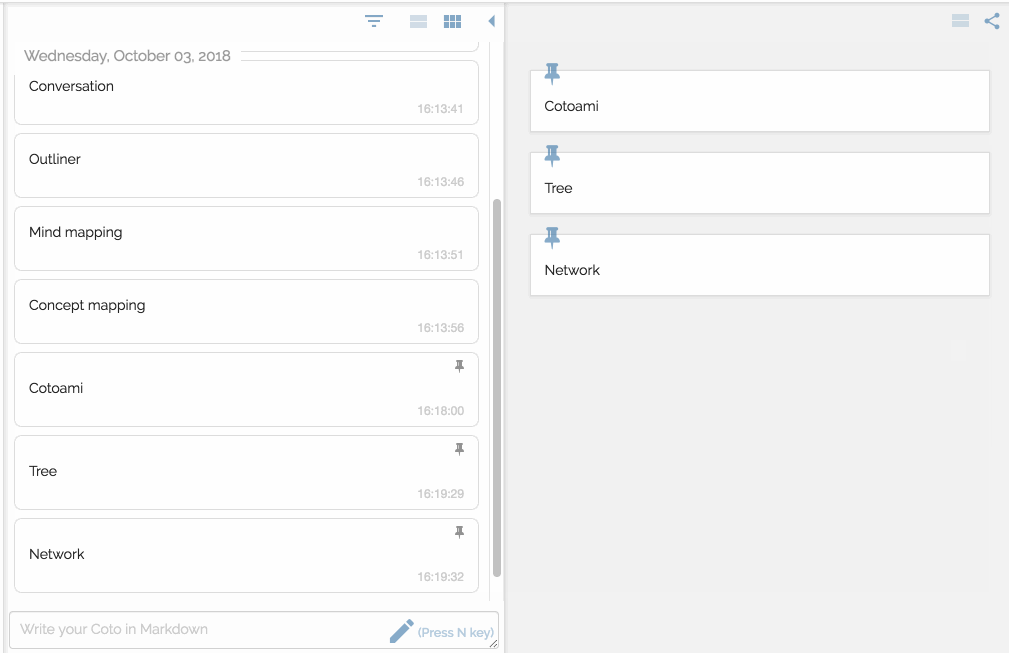
There are two panes side by side representing flow and stock respectvely.
Then you make connections to enrich your stock just like Piggydb’s fragment relationships.
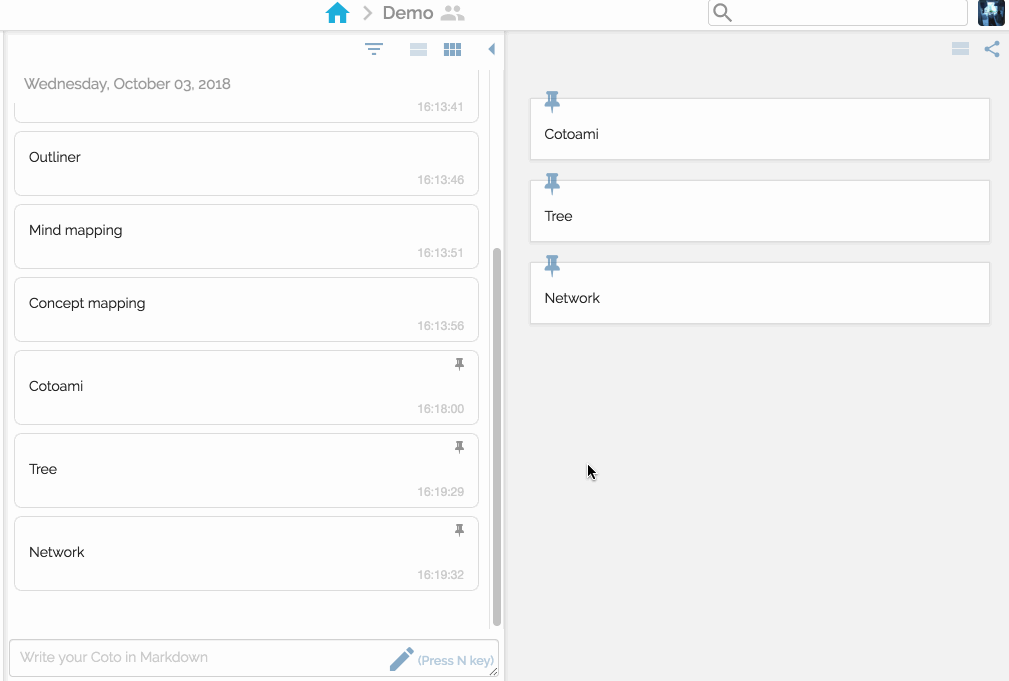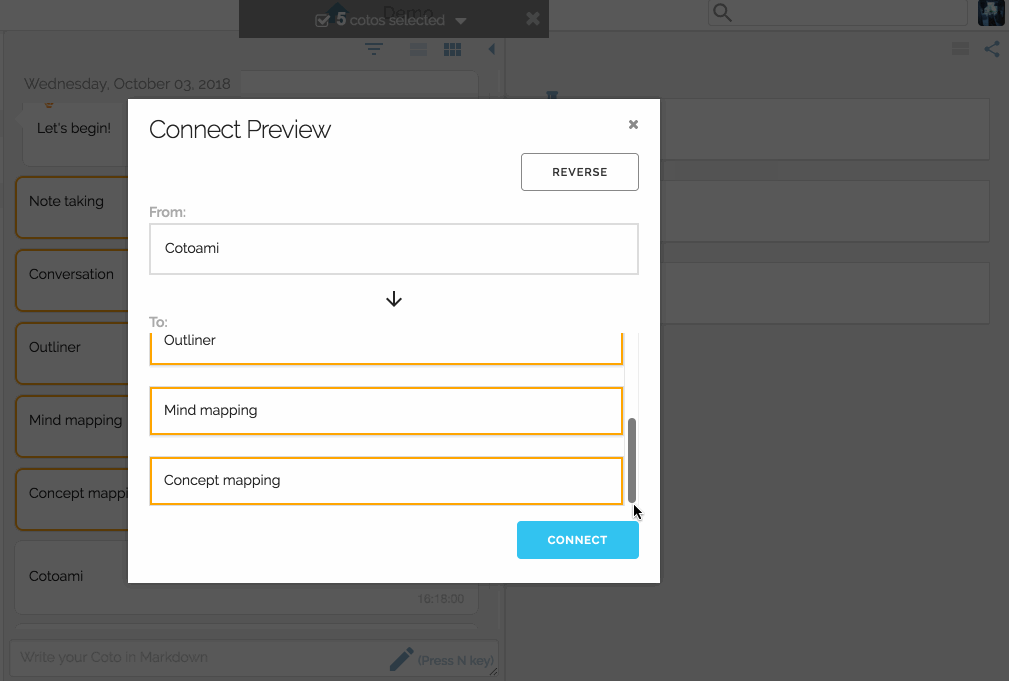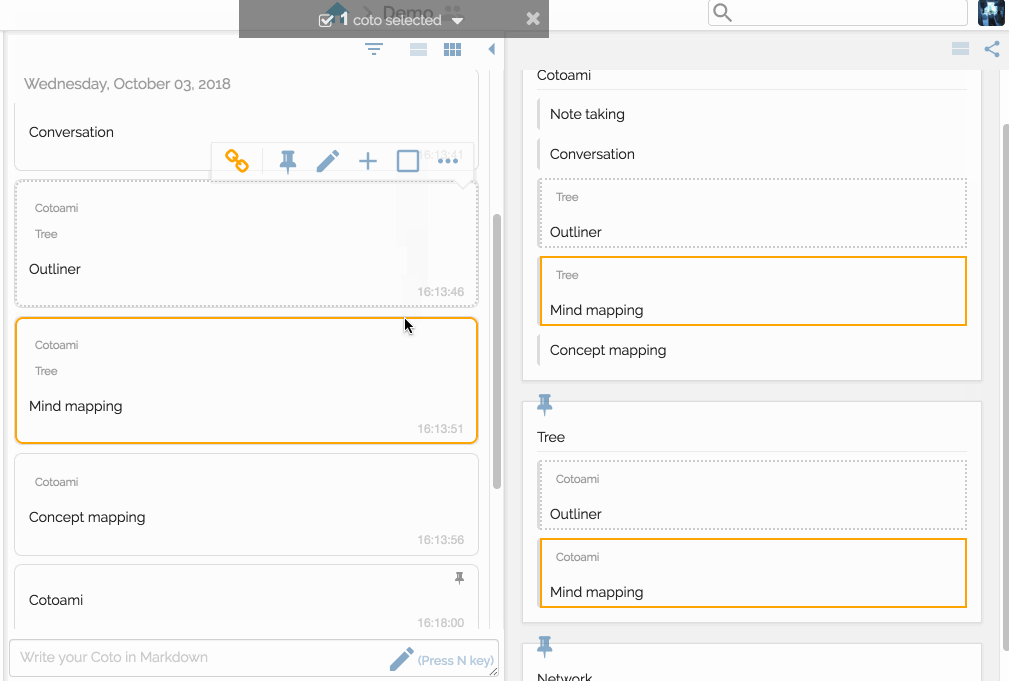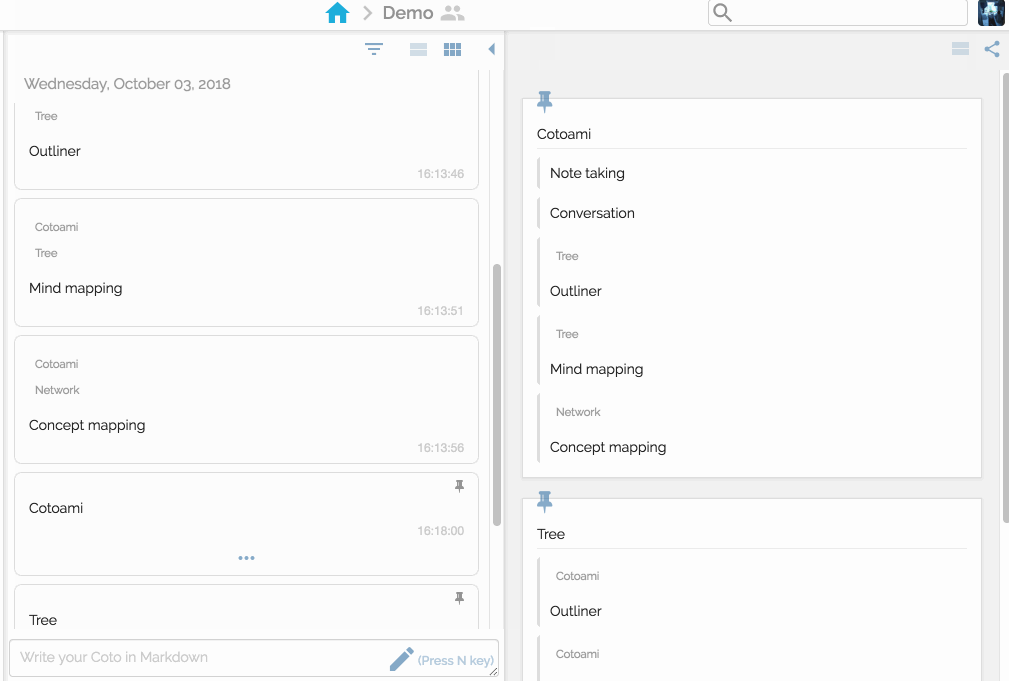
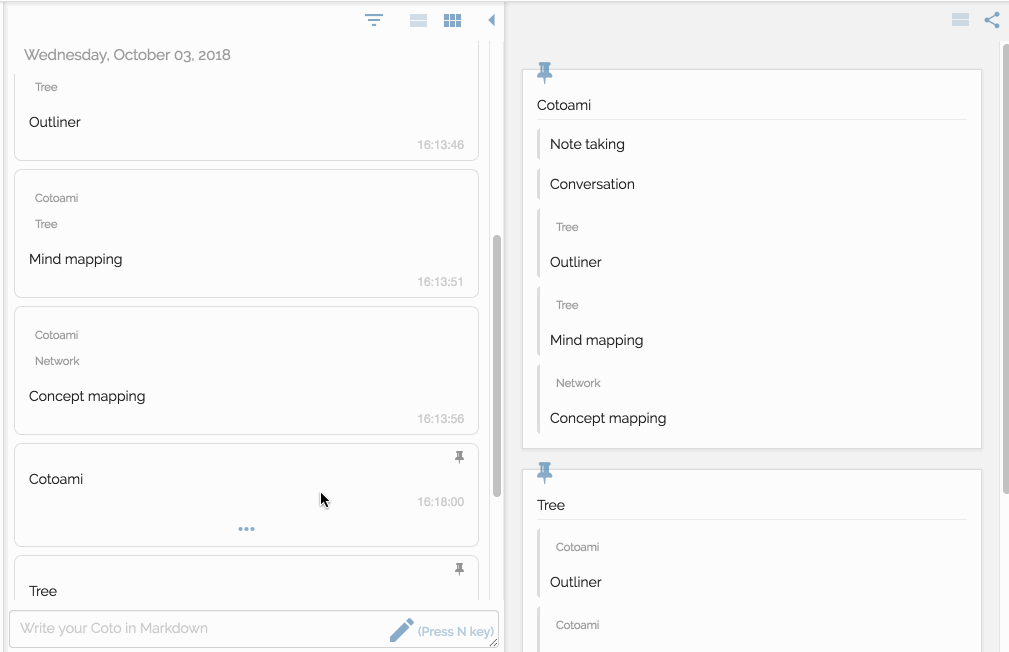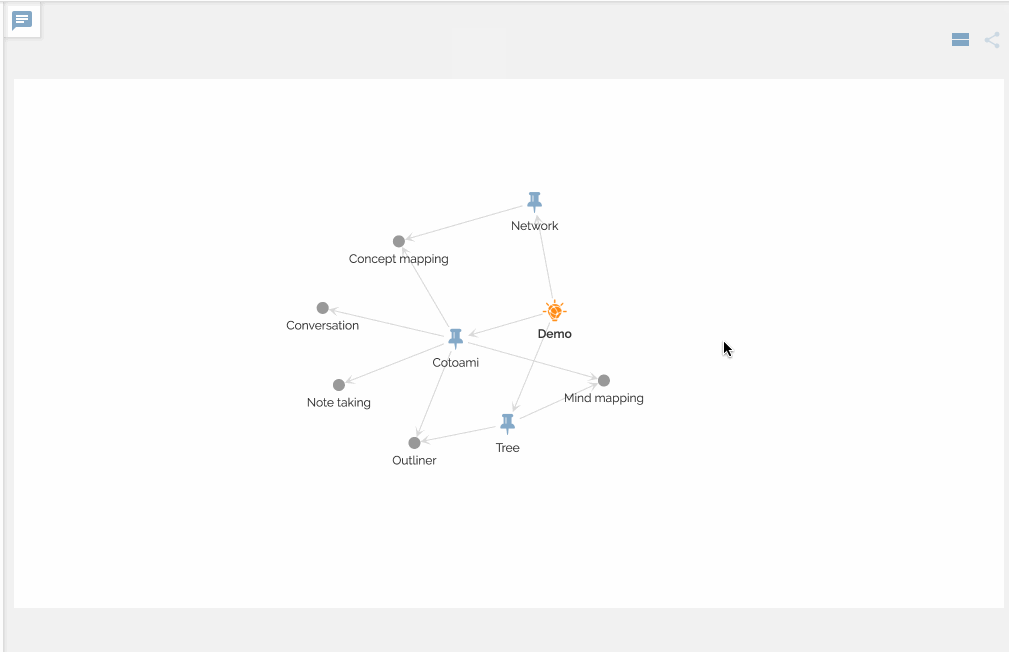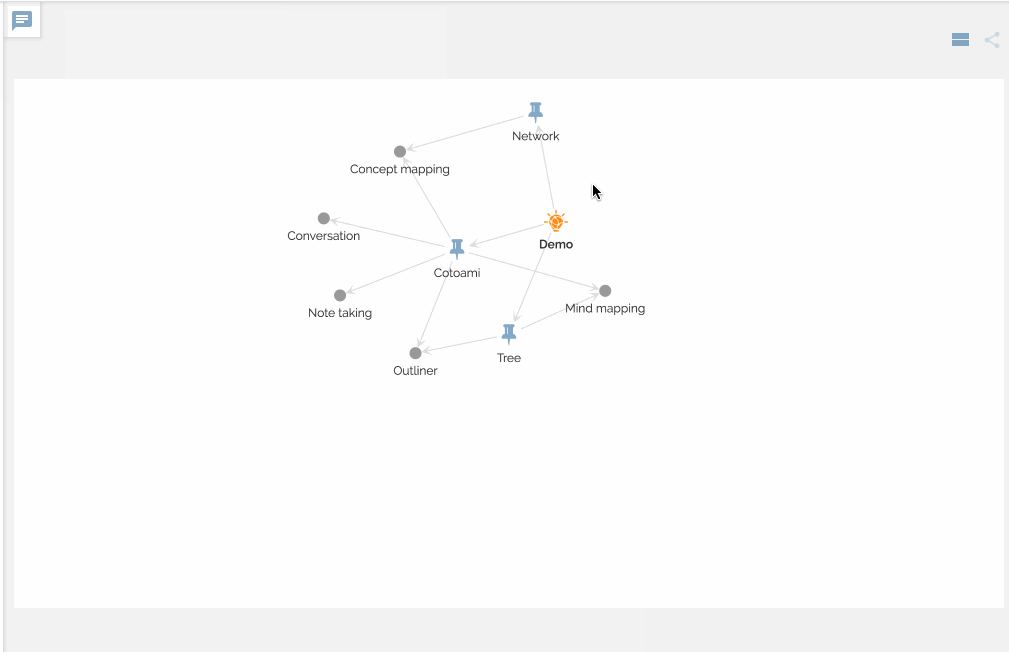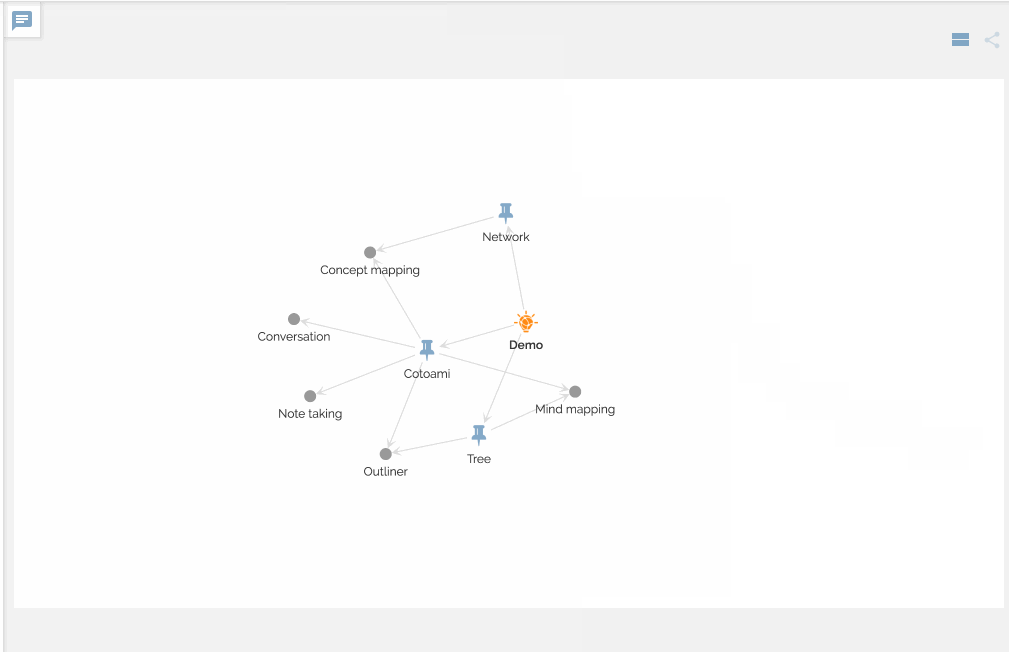
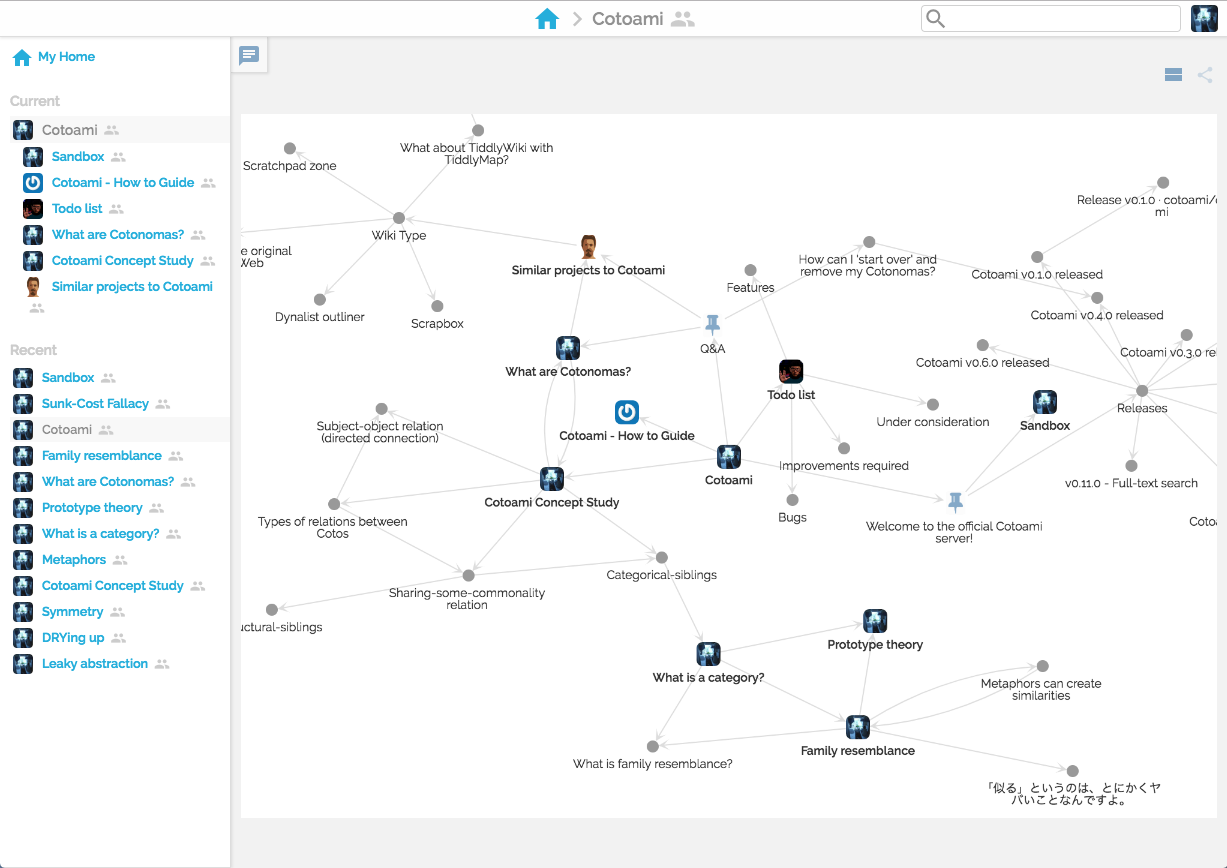
You can view your network of knowledge in a graph:
Making connections is like chemical reactions in metabolism, which should produce a new chemical substance finally. And this is the second principle implemented as “Cotonomatization” in Cotoami.
In Cotoami, individual posts are called “Cotos”, which is a Japanese word meaning “thing” and there’s a special type of Coto called “Cotonoma” (Coto-no-ma means “a space of Cotos”). A Cotonoma is a Coto that has a dedicated chat timeline associated with it.
These two concepts are basic building blocks of a knowledge base in Cotoami.
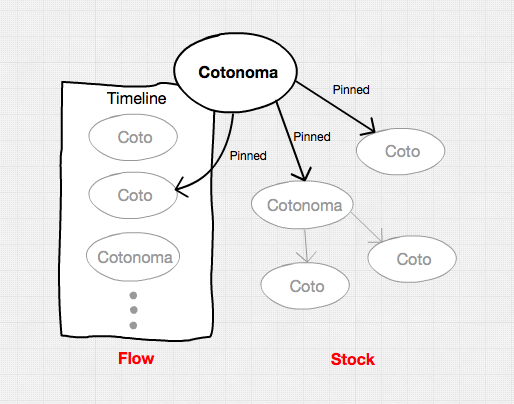
As you can see in the above image, Cotonomas form a recursive structure and each Cotonoma has its own metabolism cycle.
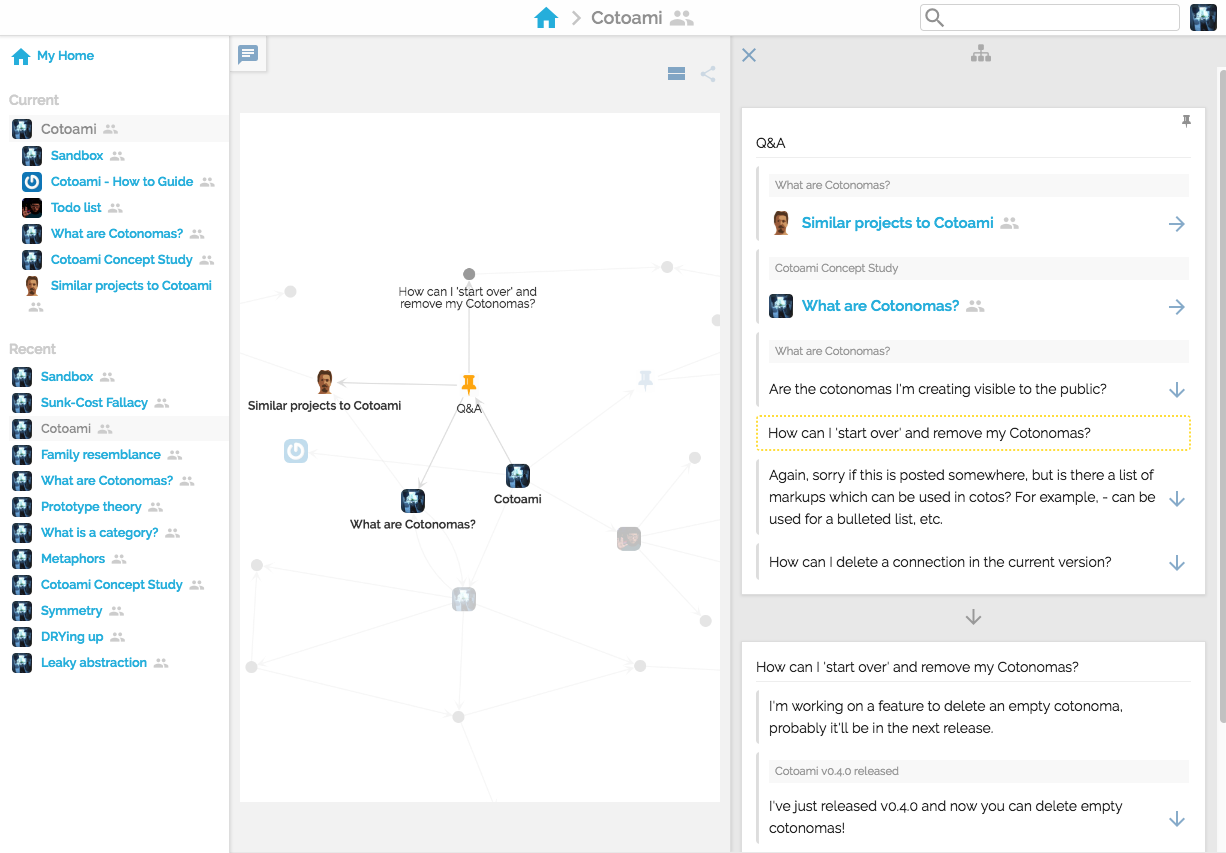
Here you can understand what “Cotonomatization” is. It means converting a plain Coto into a Cotonoma:
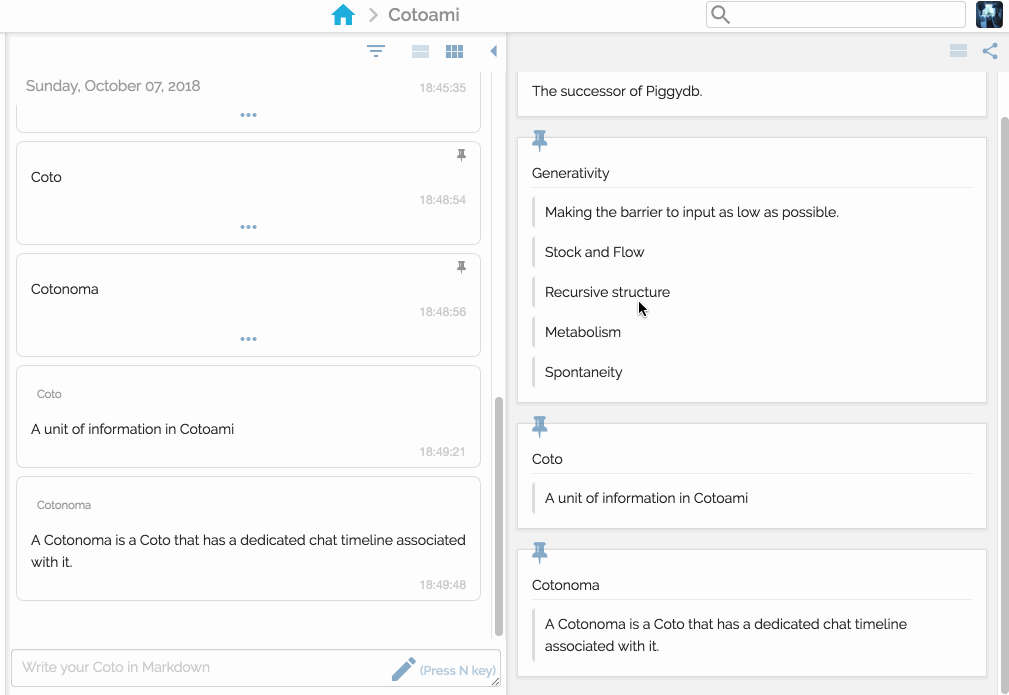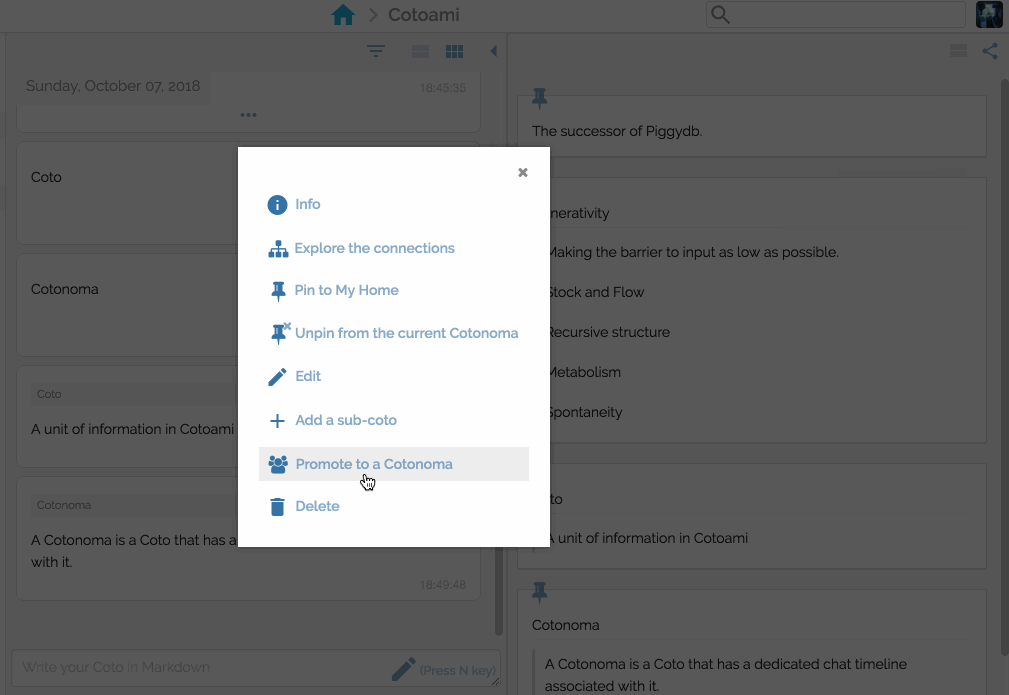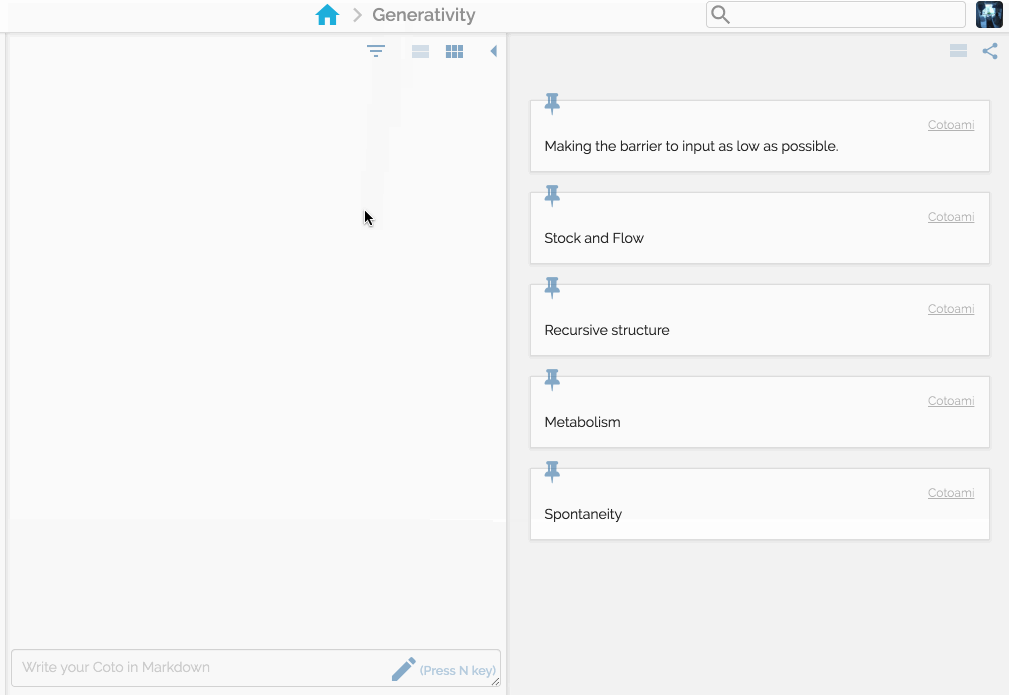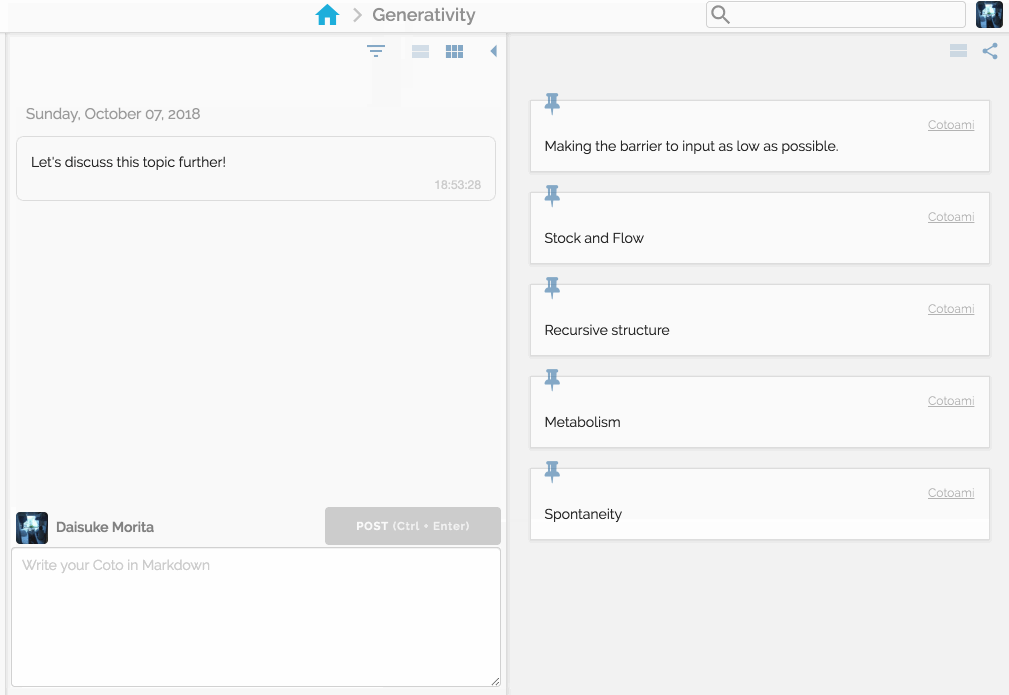
I think this process, converting a Coto that has collected many connections and appears to be important into a Cotonoma, in order to create another conceptual space of metabolism, leads to what I originally thought in 2010: “some sort of structure would gradually emerge in the continuous organization”.
I’ve been using Cotoami for more than a year now and feel it works greatly. Many of my Cotonomas have been created spontaneously from my random thoughts or conversations with my friends and they are filled with new discoveries.
I’d like you to try it out if you read this far 😉 There’s a demo server: https://demo.cotoa.me and another server for practical use, which gives accounts to crowdfunders: https://www.patreon.com/cotoami
Piggydb -> Oinker -> Cotoami: We need your help!
Posted: April 4, 2017 Filed under: uncategorized Leave a commentHello!
After the experimental endeavour to create a next-generation Piggydb which became Oinker.me, we decided to re-create it from scratch as open source.
The project is called “Cotoami”. It is still in an early stage of development and we are looking for some comments and feedback from people who are interested in Piggydb-like applications.
You can easily catch up on the history of development by reading the tweets at https://twitter.com/cotoami and try out the latest version at https://cotoa.me
- Cotoami – https://cotoa.me
- Twitter – https://twitter.com/cotoami
- Cotoami GitHub repositories – https://github.com/cotoami
- Cotoami Roadmap – https://github.com/cotoami/cotoami/issues/2
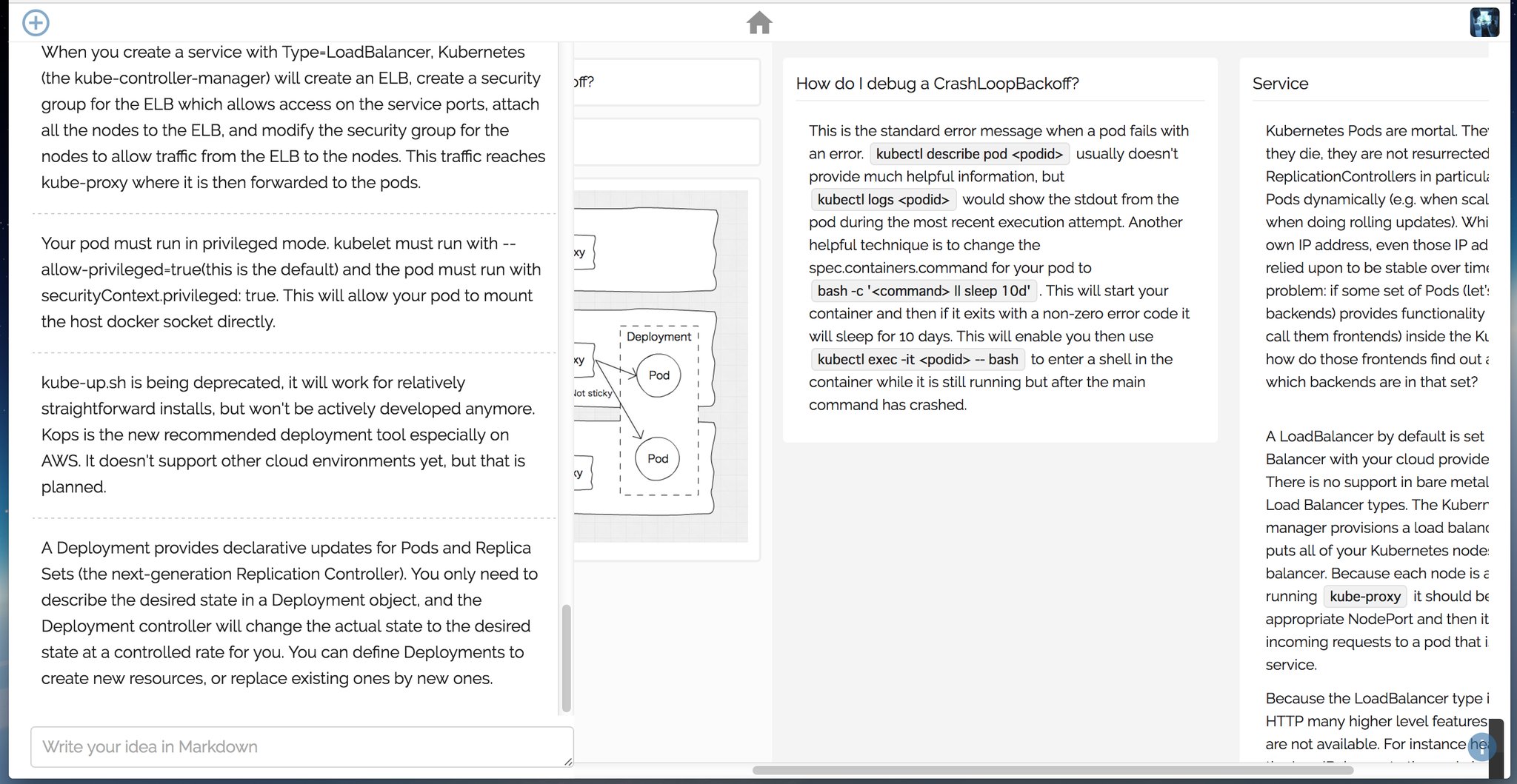
Piggydb V7.0 – Java 8 / New Page Header / Bug Fixes
Posted: February 16, 2016 Filed under: uncategorized 2 CommentsHi there,
It’s long time no see… actually, it’s almost two years since the last version (V6.18) was released.
After the long pause, Piggydb’s new version is finally here.
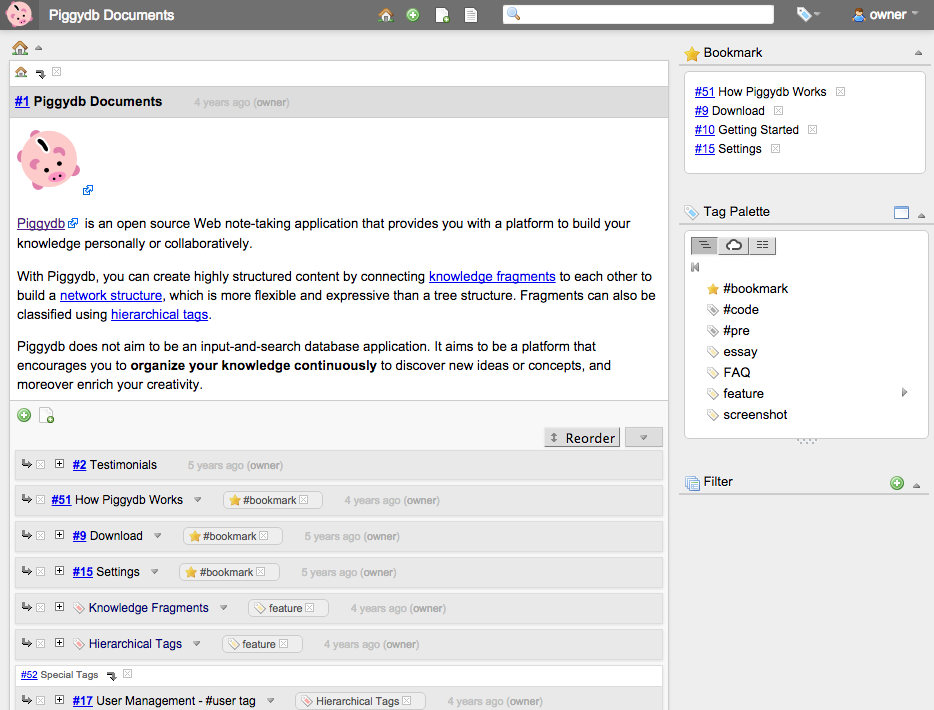
It doesn’t contain big changes except that the page header has been redesigned. Now it looks cooler than before (hopefully), and the title displayed in the header (“Piggydb Documents” in the screenshot) is the “Database Title” which you can change in the System Info page.
It also fixes a bug that it won’t work offline because of the reference to the hosted Mathjax library.
- Mathjax load from cdn makes Piggydb unusable without internet connetction · Issue #9 · marubinotto/Piggydb
Lastly, Piggydb V7.0 requires Java 8. If you use one of the previous versions of Java, you need to upgrade it.
Enjoy 😉
Knowledge Network Graph Visualization
Posted: October 25, 2015 Filed under: uncategorized 5 CommentsFrom time to time I received requests for MindMap or ConceptMap like graph visualization (nodes and edges style) in Piggydb or Oinker. But I thought there were things to consider in order to implement it since the models in both applications were document-oriented as I explained in an Oinker Blog entry.
- Graph Style (Nodes and Edges) or Document Oriented Style? | Oinker Blog
Recently I came up with an idea and implemented it in Oinker as below:
The problem of displaying document-oriented data in a graph view is that a document tends to contain many large nodes which are not suitable for bird’s eye overview. So we should deal with these nodes somehow to avoid the verbosity of being precise. The idea I came up with is a way to select nodes for a graph. I call these selected nodes “topic nodes“.
Currently a topic node is:
- a node whose content has only one word or sentence.
- a node whose content length is shorter than or equal to 30.
- a node whose content is not Markdown
- a node whose content is not a URL
- a node whose content is not a file
You can check out an example of how topic nodes work in Oinker’s graph view at:
https://oinker.me/room/marubinotto/impact-mapping
This feature is still experimental and waiting for your feedback.
Oinker – https://oinker.me/
Piggydb and Oinker as a Content Publishing Platform
Posted: August 26, 2015 Filed under: uncategorized Leave a commentHi there,
It’s been a while. These days I’m working on a web service “Oinker” off and on, squeezing time from busy days.
Recently, I’ve started pulling well-proven features from Piggydb and adding them to Oinker. One of them is a content publishing capability which is implemented as “Anonymous Access” in Piggydb (sample site).
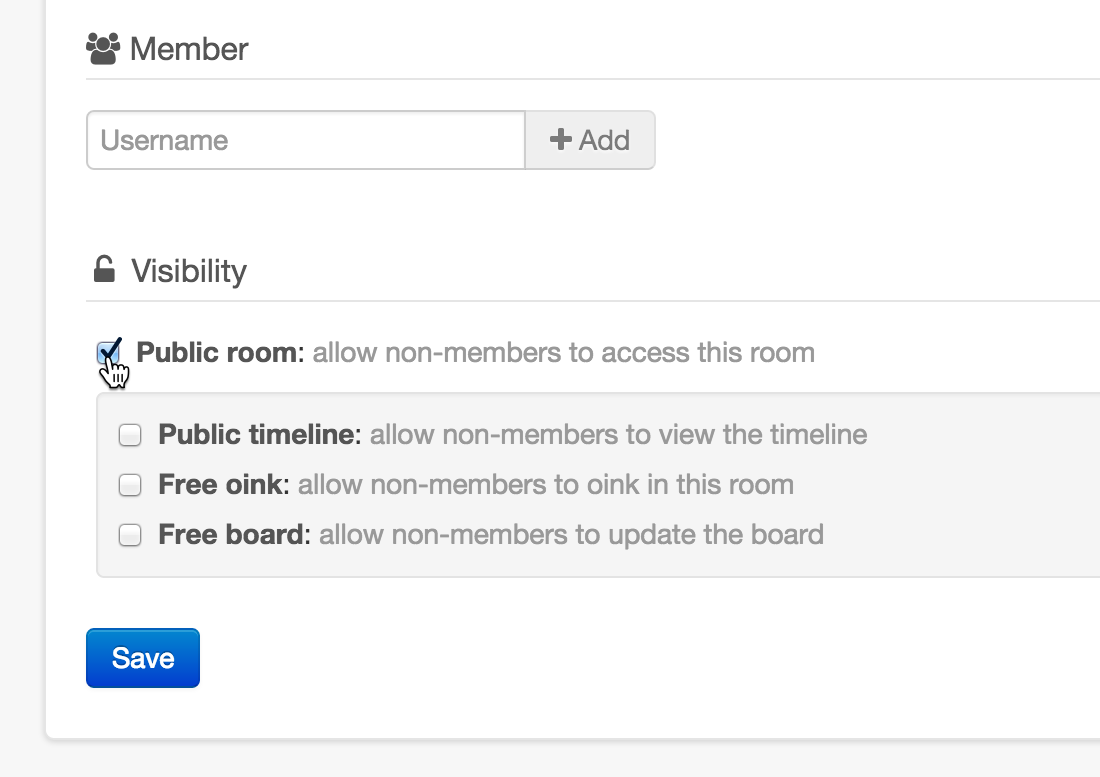
Oinker’s publishing feature is more sophisticated than Piggydb. You can publish your content on a room basis. A room is like a chatroom in Oinker and it has a chat timeline and a board on which you create content with your roommates.

A room is composed of a timeline and a board
You can make a board open to public so that anonymous visitors can view the content, and additionally allow logged-in users who are non-members of the room to view the timeline and post messages to it. So you can not only publish your content, but also collect feedback from audience.
What kind of content can you create in Oinker? Just check out the sample content: Unknown Tokyo



Recent Comments