
Piggydb V6.17 – Incremental Search by Tag and MathJax Support
Posted: February 16, 2014 Filed under: uncategorized 6 CommentsFirstly, this release extends the fragment incremental search to support tags in addition to keywords. You can add tags for the list to include or exclude the fragments with the specified tags as follows:
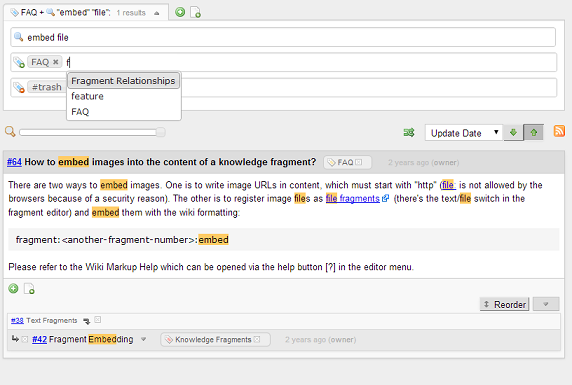
The list will be automatically refreshed as you edit the criteria (keywords, tags). This incremental search is going to replace the filter feature which will be removed in coming versions.
Secondly, the release adds MathJax support that allows you to embed mathematics notation by writing LaTeX expressions in the content:
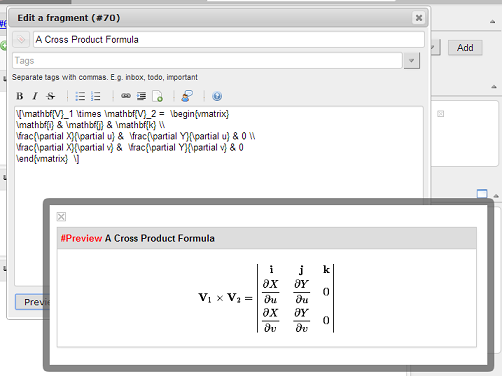
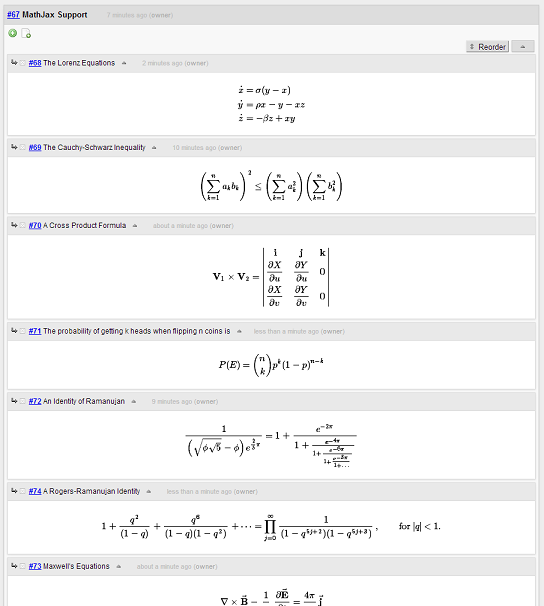
And lastly, the global search box has been cleaned up a little bit, removing the redundant buttons.
You can download the latest version from: https://sourceforge.net/projects/piggydb/files/latest/download
Linux Magazine: Organize and access data with Piggydb
Posted: February 3, 2014 Filed under: media article Leave a comment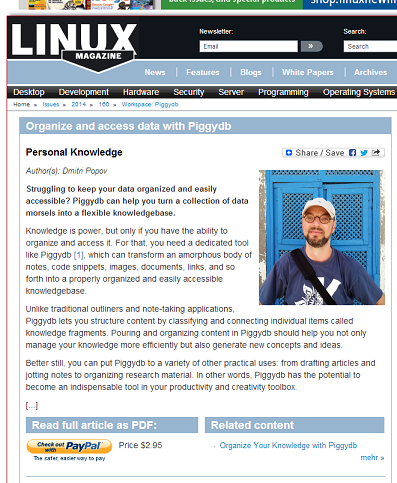
Dmitri Popov, a technical writer covering Linux and open source software, wrote an extensive article on Piggydb for Linux Magazine. It covers various topics: what Piggydb is all about, detailed instructions on how to set up and use it, etc.
To be honest, I think it is the best article on Piggydb I’ve ever read. So if you are looking for a definitive guide to enter the Piggydb world, it is definitely worth checking out.
http://www.linux-magazine.com/Issues/2014/160/Workspace-Piggydb
Feature request: Fragment-based filtering
Posted: February 2, 2014 Filed under: discussion 3 CommentsPiggydb user Novbert posted his thought on the problems of Piggydb’s filters on the issue tracker. I think his feedback is to the point and am beginning to think about removing or overhauling the current filter feature in the coming versions of Piggydb.
I’d love to hear from you on this topic, so please post a comment on this article if you have any opinions.
I don’t particularly like the way filters are integrated into the piggydb concept. Actually I think they are part unnecessary and part redundant. One could argue, that they are there as shorthands for any meaningful set of concepts, but we have tags for the very same purpose, rigth? Even if we argue, that there are useful sets of tags we want to leave untagged, that set should probably also be a concept in itself, thus filters should be fragments themselves, shouldn’t they?
Actually this way of thinking also works in the opposite direction. Fragments could be used as filters for the sum of tags assigned to them. Would that be the case, having filters as a separate entity would be totally unnecessary.
Let me tell an example. I’m building a DB on all types of fiction, movies, books, comics, etc. I categorize them based on genre, media, author, etc. Naturally I have tags like Movies, Books, and also Sci-fi, Fantasy. Though having a category for “Sci-fi movies” sounds rather intuitive, how would I do that in piggydb? I don’t want to set it up as a tag, as I already have a set of tags for this, so it would make my tag system redundant by assigning both “Sci-fi” “Movies” and “Sci-fi Movies” tags to all the relevant fragmens. But if I set it up as a filter, I lose the ability to make general notes on the subject. Of course I could solve the problem by creating a fragment called “Sci-fi movies” and assign all the specific movies as child fragments, but that would result an organized list of movies, while I’d like to see these as a set, while making general notes on them (e.g. : the history of Sci-fi movies, notable directors, etc.) I’d like to look at this summary fragment, and edit it, while browsing through all the specific movies.
Which brings me to my next point: the uselessness of the middle and right pane when focusing (clicking) on a non-tag fragment. If I do that, the fragment content appears on the left, leaving a useless view of all my fragments in the middle (which can be filtered by keyword, but not by tags), and a similarly useless right pane, without tag-based filtering ability.
I think it would make much more sense if it would work like this:
– Clicking on any non-tag fragment wouldn’t only show the contents on the left, but it would also make the middle and right pane behave as if I’d have set up a filter with all the tags assigned to that segment. Changing filter parameters would only affect the middle and right pane, the chosen segment would remain active on the left as long as I don’t click on another one.In the above scenario it would result this:
I could set up a non-tag fragment called “Sci-fi movies” and assign tags “Sci-fi” and “Movies” to it. If I click on that fragment, it would appear with all the details on the left, while all the actual sci-fi movies with tags “Sci-fi” and “Movies” assigned would appear on the right, with ability for further filtering based on both keywords, and tags. I could overview all of them, while looking at my summary fragment, and I could even try to find relevant fragments in other categories e.g. by removing Sci-fi from the filter criteria and add another related tag like “James Cameron”. All this, while still looking at my summary fragment called “Sci-fi movies”
Similarly if I’d click on any actual sci-fi movie (e.g. Avatar, with tags “Sci-fi”, “Movies” and “James Cameron” assigned), in the middle pane there would appear all the movies falling in exactly the same category (e.g. Alines, The Abyss and Terminator 2), and I could even try to find related concepts e.g. by removing Cameron from the tag filter criteria and inserting another director.)
As I see this way of working might as well make Filters as separate entities entirely unnecessary for piggydb, as users would have the ability to filter fragments based on tags (as it is right now), and fragments themselves would behave just like filters, thus if the user finds any important pattern/set in the database, he could create a fragment with the relevant tags assigned, making himself able to query that set later on at any time. That later step would even be unnecessary as any set of fragments with the same tags applied would behave like a filter for itself.
What do you think?
Piggydb Use Case: Relationships(Links) for Quick Reference
Posted: December 25, 2013 Filed under: uncategorized Leave a commentPiggydb user David Shrader kindly shared his experience of using Piggydb for his study. He utilizes piggydb’s relationships(links) to allow him to quickly access basic information to learn via Fragment Quick View.
—–
I was in class training to earn my Oracle OCA certification, and I was having a lot of trouble studying for the 1z0-151. I had my notes in a notebook, and I found that if I read over the “key facts” I was reading a lot more than necessary about certain elements, and not enough about others. I passed my test, but only by 4 points.
Fast forward to studying for my 1z0-152, and I knew that I had to do something different to learn the material. In addition to staying up many late nights studying, I also began using piggydb to take notes and link pieces of knowledge together. The most beneficial thing for me was being able to create links (example syntax [fragment:99 BASIC INFO]) to knowledge fragments, allowing me to hover over the links to glance at information I already knew, and if I realized I didn’t understand something well enough I was able to open the link and read over the entire concept in depth. This may not sound very helpful, but for my learning style it was perfect. I was able to include charts and tables in the fragments for each key term, and I wasn’t forced to have them in the same (illogical) order as the books. I displayed storage charts from the largest to smallest element, etc. Then I was able to link the knowledge fragments together when they were related, which also helped cement the information in my mind.
So what was the final outcome you might ask? I scored a 93 on the 1z0-152. My instructor was shocked. Just for the sake of comparison, I scored a 64 on the first exam. That’s a 29% improvement thanks to piggydb, lol.
—–
Thanks, David!
Let’s Play: Piggydb Knowledge Creation #4 – “Metaphors We Live By” by George Lakoff, Mark Johnson
Posted: October 29, 2013 Filed under: letsplay Leave a commentIt’s been a while since the last installment. It is partially because this time I took up a book with structure-rich content: an academic essay.
“Metaphors We Live By” is the book I selected this time. It is one of the cornerstone books of cognitive linguistics, dealing with conceptual metaphor, which, according to this book, plays a central role in defining our everyday realities.

I’m not a specialist in this field at all and haven’t studied it before. So it was a time-consuming task for me to digest the content and somehow restructure it on Piggydb.
As a result, it produced far more knowledge fragments and a complex structure than before. And it’s also the most abstract topic in this series because it deals with the cause of our intelligence.
– http://piggydb.jp/example/fragment.htm?id=60
– http://piggydb.jp/example/d/60 (Document View)
As the number of the fragments grew, I felt it was important to try to make a title for each fragment. It’s good for both to grasp your knowledge-base later and understand what you have quoted from a book. A shorter title would be better, and if a title becomes a noun, you should consider to put the fragment in a higher place. A key to comprehend a complex idea is to rearrange the content in a concept(noun)-oriented way. If you look into the example in the above links, you’ll see most of the top level fragments have a noun as their title.
In the course of dealing with such a complex content, I felt Piggydb should become more expressive. The book contains many new ideas found after it was first published and updates of the old ideas explained in the original content. To express these subtle relationships, I think it needs to improve in terms of fragment’s relationships.
Piggydb V6.16 Supporters Edition: Embed GitHub Gist
Posted: October 19, 2013 Filed under: supporters Leave a commentAnother bonus feature to the Supporters Edition: embedding a snippet from Github Gist, which is a popular website where you can share snippets and pastes with others.
To embed a snippet, just put a Gist URL:
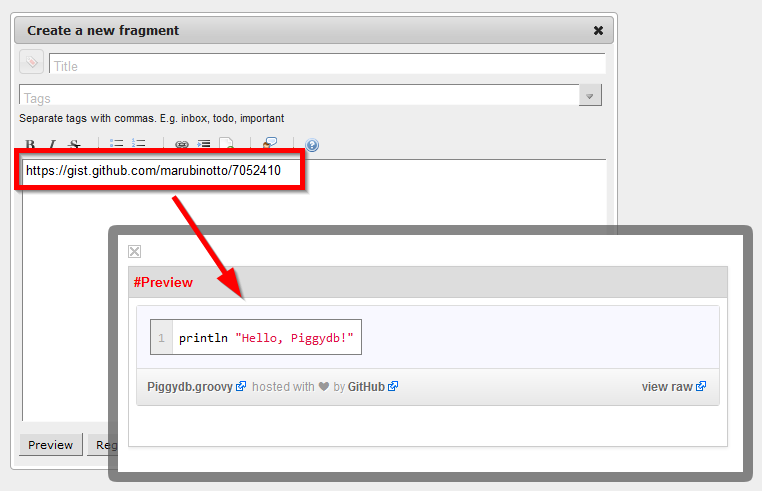
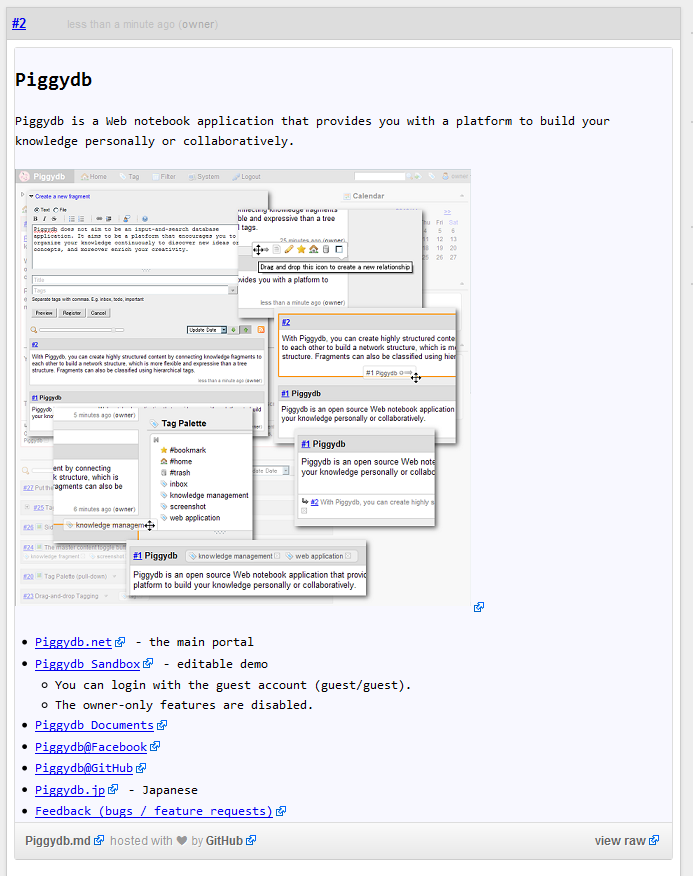
Github Gist allows you to share not only program code snippets, but also plain HTML documents written in Markdown:
If you are new to the Piggydb Supporters Edition, please check out the articles in the ‘supporters’ directory: https://piggydb.net/category/supporters/
Click here to buy Piggydb Supporters Edition (Thank you for your support 😉 )
Piggydb V6.16 – Fragment Quick View
Posted: October 19, 2013 Filed under: uncategorized Leave a commentPiggydb has provided you with ways to easily navigate through a knowledge-fragment network, for example, the tree and list views. This release adds another alternative to these navigation features: Fragment Quick View.
It allows you to move through a network, fragment by fragment, more lightly.
Mouse hovering over a link to a fragment for a second brings up a pop-up view for the fragment:
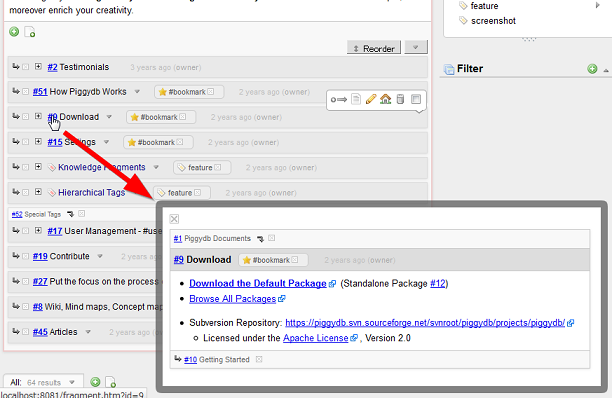
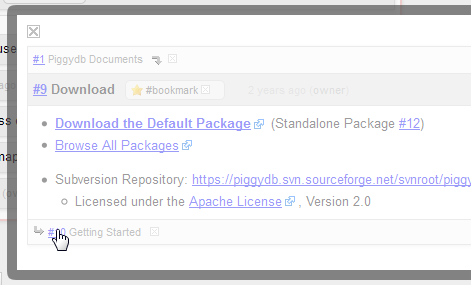
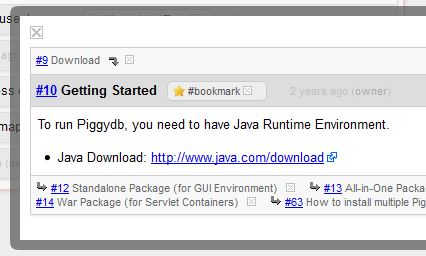
In the pop-up view, you can move to another fragment via links (the parents, children or links in the fragment content):
You can download the latest version from: https://sourceforge.net/projects/piggydb/files/latest/download
Piggydb V6.15 Supporters Edition: Embed Ustream Videos
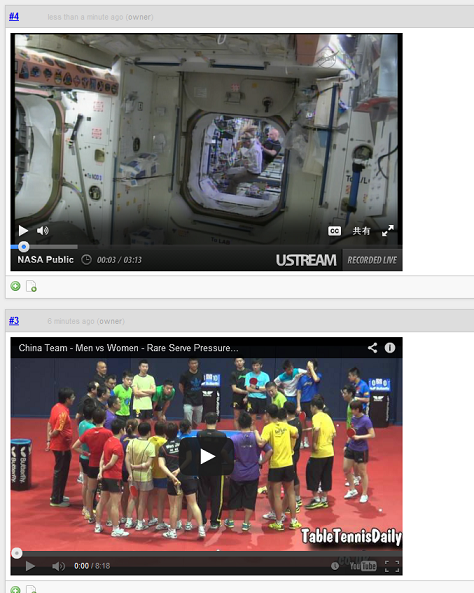
Posted: September 18, 2013 Filed under: supporters Leave a commentFinally, though it is a small one, I’ve added a new feature, which is exclusive to the Supporters Edition.
You can now embed Ustream videos into your knowledge fragments just by putting video URL like: http://www.ustream.tv/recorded/38909163
With this as a starting point, I’m going to add further Wiki-formatting extensions in coming versions of Supporters Edition.
If you are new to the Piggydb Supporters Edition, please check out the articles in the ‘supporters’ directory: https://piggydb.net/category/supporters/
Click here to buy Piggydb Supporters Edition (Thank you for your support 😉 )
Piggydb V6.15 – Tag Icons for Each Type of Tags
Posted: September 18, 2013 Filed under: uncategorized 2 CommentsThis release changes the tag icons to have different colors according to the types of tags:
System Tag (starting with ‘#’ and used for management purposes):

Plain Tag:

Tag Fragment:

This update would be important more than you think, because tag-fragments are the most important parts of Piggydb database and the new version allows you to easily recognize your tag-fragments from the others.
![]()
You can download the latest version from: https://sourceforge.net/projects/piggydb/files/latest/download
Piggydb V6.14 – Expand Sub-fragments After Reading Content
Posted: September 2, 2013 Filed under: uncategorized Leave a commentHave you ever encountered a situation that you had read a long fragment and subsequently wanted to read its sub-fragments, but it was quite frustrating to scroll back to the fragment header to click on the tree toggle button?
This version fixes this problem by adding a button at the bottom of the content:
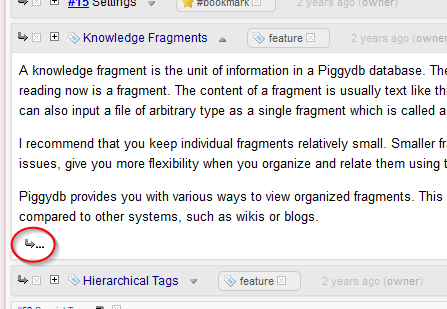
Clicking on this button expands the sub-fragments like the tree toggle button does:
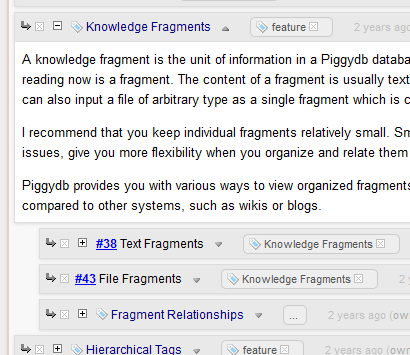
—-
This version also adds support for non-ascii file names when you upload files as file fragments.
—-
You can download the latest release of Piggydb from: https://sourceforge.net/projects/piggydb/files/latest/download


Recent Comments