
Why it’s harder to discover valuable knowledge in tree-structured note-taking
Posted: March 6, 2019 Filed under: uncategorized Leave a commentRecently, Cotoami project, the successor of Piggydb, released a new feature called “Linking Phrases”.
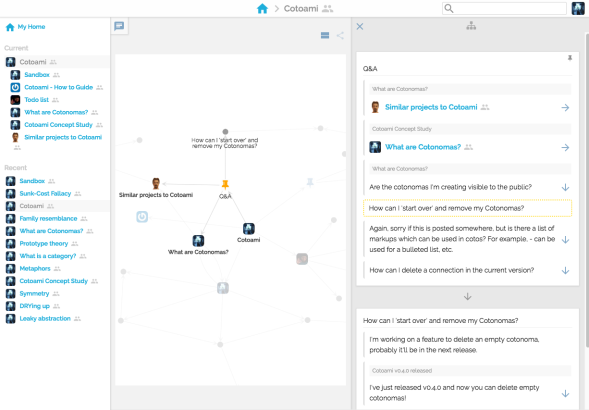
As you can see in the screenshot below, it allows annotating a connection when you feel a need for some explanation of it.
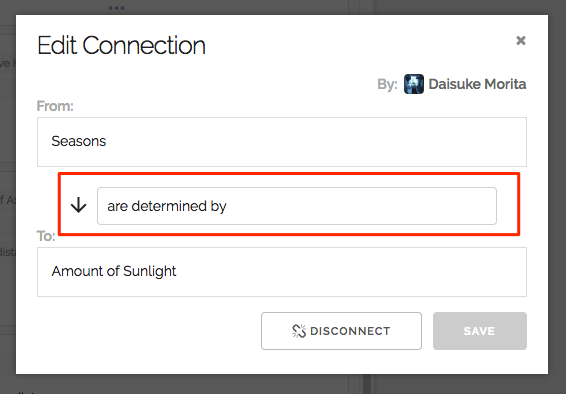
I thought about this enhancement when I was working on Piggydb some years ago but suspected it would just complicate things without adding much value. Piggydb aimed at becoming a simple note-taking tool, not a modeling tool. After all, you can express a labeled relationship by adding a node between the two.
However, I came up with an idea of “Horizontal and Vertical Relationships” recently and thought it would become one of the significant features in Cotoami.
The term “Linking Phrases” is borrowed from Concept Maps, which I mentioned in the article Wiki, Mind maps, Concept maps, and Piggydb before.
When I first saw concept maps, I thought that is where Piggydb’s knowledge creation process should lead.
Since it focused on the structure or knowledge-creation-process side of Concept Maps, Piggydb hasn’t had an update to support writing Concept Maps so far, but now, Cotoami supports it as a result of this enhancement.
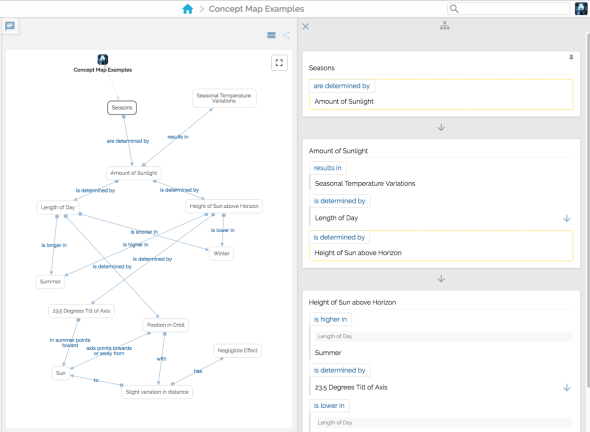
The above concept map explains why we have seasons (the original concept map is presented in the article at Concept Maps official website: http://cmap.ihmc.us/docs/theory-of-concept-maps). If you are interested in how this concept map was created with Cotoami, here is a youtube video to demonstrate the process:
Concept mapping is an excellent way to demonstrate this feature, but a significant difference is that Cotoami’s linking phrases are optional. That means you should avoid annotating connections unless the relationships are obscure to you. Those unclear relationships are possibly valuable knowledge for you (since you didn’t know them well before), and should be highlighted in your knowledge-base. I call them Horizontal Relationships.
On the other hand, Vertical Relationships generally means inclusive or deductive relationships like “has”, “results in”, or “is determined by” appeared in the concept map example above. Most connections would fall into this category. Simple arrow lines would be enough to express these relationships, and you wouldn’t feel the need for annotations in most cases.
Whether a connection is horizontal or vertical depends on you or your group. For example, if you are a table tennis fan, the connection below should be obvious:
[Table tennis] ----> [Jan-Ove Waldner]
But if you are not, there’s a need for some explanation:
[Table tennis] --(legendary player)--> [Jan-Ove Waldner]
In the process of Cotoami’s knowledge creation, horizontal relationships would be a small portion of all connections but represent some important discoveries in your knowledge-base. That’s why I introduced this enhancement. Annotating only horizontal relationships won’t complicate things.
This idea also leads to the insight described by the title of this article. It would be difficult to deal with both horizontal and vertical relationships at the same time in tree structures which mainly deal with the latter.
With this update, Cotonomas (Cotonomatizing), which I explained in the previous entry, and Linking Phrases are the most two essential features so far in Cotoami. Both are for highlighting your discoveries.
If you are interested in Cotoami’s way of note-taking, check out the project website on GitHub (https://github.com/cotoami/cotoami). It would be fairly easy to try it out on your PC.
The project is also waiting for your support by becoming a patron at https://www.patreon.com/cotoami. In return, you’ll get an account of the fully-managed official Cotoami server.
The 10th anniversary of Piggydb and the current status of the journey
Posted: October 7, 2018 Filed under: uncategorized 2 CommentsHello.
Piggydb turned 10 this summer. It was August 27, 2008, when I released the first version.
Recently the project is in a dormant state. It’s been more than two years since the last release (February 2016).
In 2010, I wrote about the goal of Piggydb:
But as I experimented with Piggydb’s knowledge creation, I found out that it did not work as well as expected. I thought originally some sort of structure would gradually emerge in the continuous organization of knowledge fragments with tags. But there’s something missing still in Piggydb to achieve this goal. – Wiki, Mind maps, Concept maps and Piggydb | Piggydb
So what’s the current status of the journey to the goal?
I think I’m almost there.
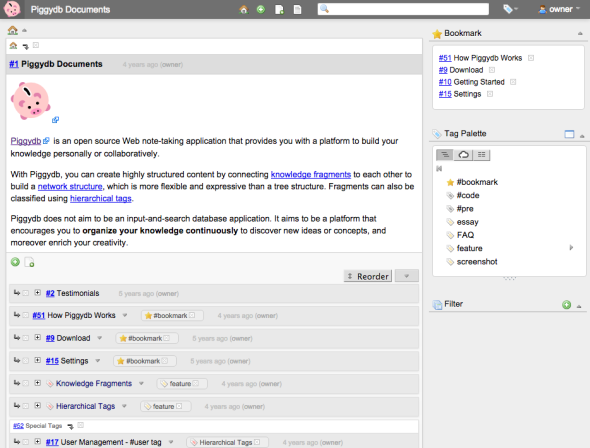
Piggydb would be powerful in terms of creating highly structured content with fragment relationships and hierarchical tags, but not good at providing a place of generativity as quoted above.
The “Table Tennis Videos” demo site is a good example for this.
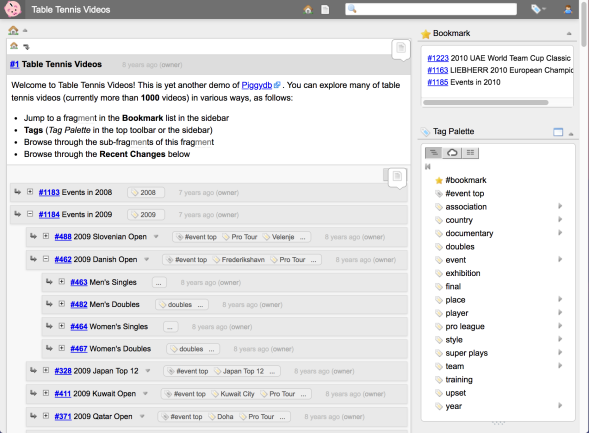
It’s well structured and tagged so that visitors can search the videos in various ways. However, once you decided a system of structure and tags, you can’t escape from it easily. You just input fragments so as to align with the existing structure.
It’s actually useful for certain purposes, especially for displaying some information, but I myself want to escape from static structures. If you use it as a personal or team knowledge base, it wouldn’t last long because it’s highly possible there’s no metabolism occurring in it.
This experience made me rethink the principles needed to realize metabolism in digital note-taking, and that led to the Cotoami project I’m currently working on.
![]()
The first principle implemented in Cotoami was to make the barrier to input as low as possible.

In Cotoami, you post your ideas and thoughts like chatting. It’s actually a chatting feature where you can chat with other users sharing the same space.
You would feel free to write anything that comes in your mind. Your posts just flow into the past unless they are pinned:
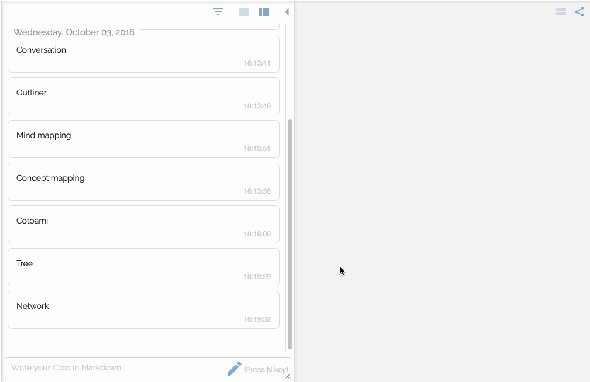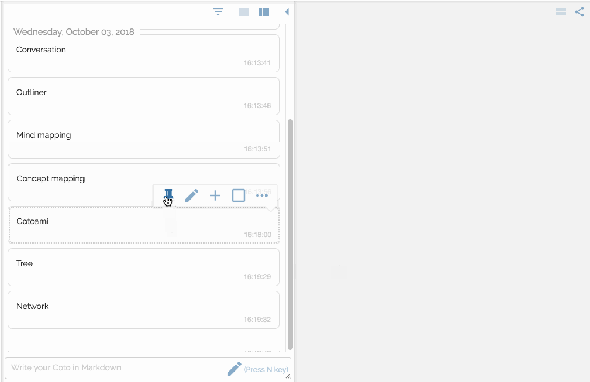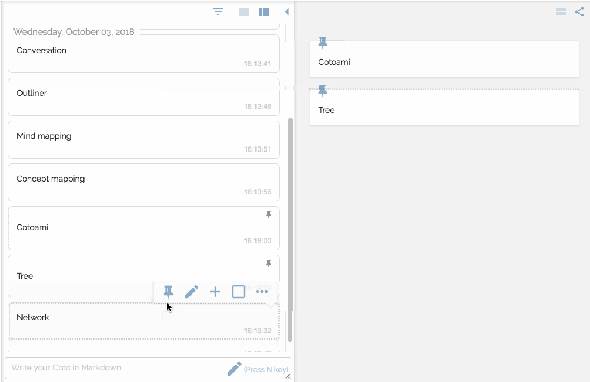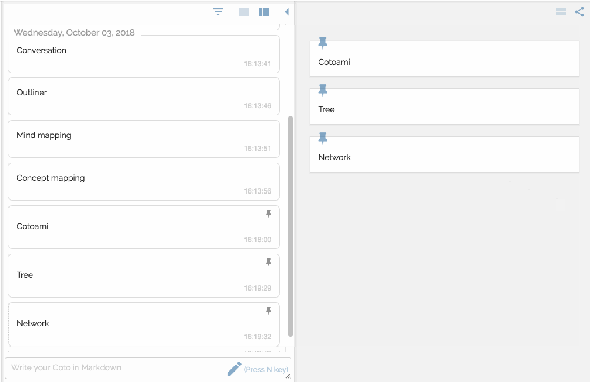
There are two panes side by side representing flow and stock respectvely.
Then you make connections to enrich your stock just like Piggydb’s fragment relationships.

You can view your network of knowledge in a graph:
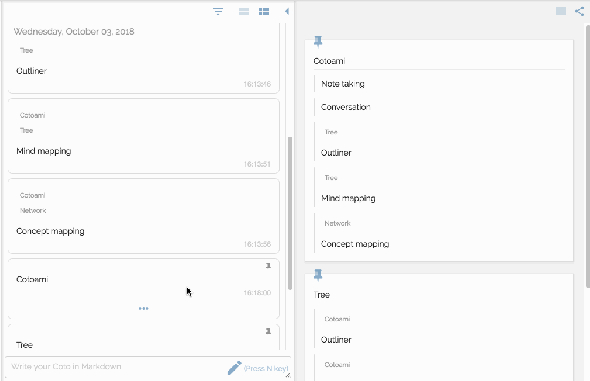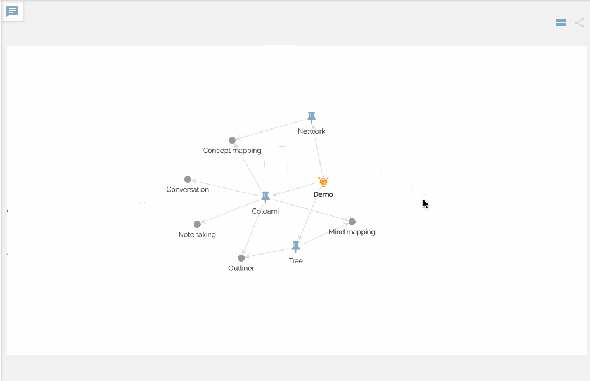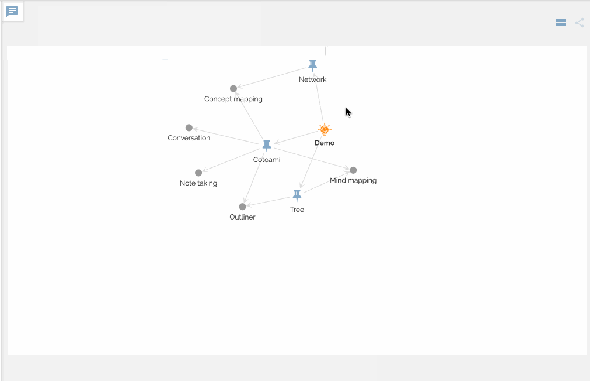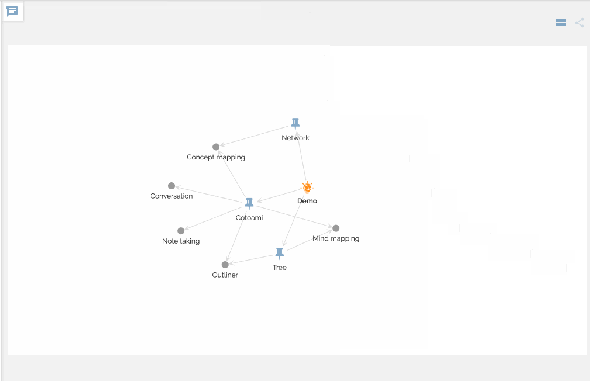
Making connections is like chemical reactions in metabolism, which should produce a new chemical substance finally. And this is the second principle implemented as “Cotonomatization” in Cotoami.
In Cotoami, individual posts are called “Cotos”, which is a Japanese word meaning “thing” and there’s a special type of Coto called “Cotonoma” (Coto-no-ma means “a space of Cotos”). A Cotonoma is a Coto that has a dedicated chat timeline associated with it.
These two concepts are basic building blocks of a knowledge base in Cotoami.
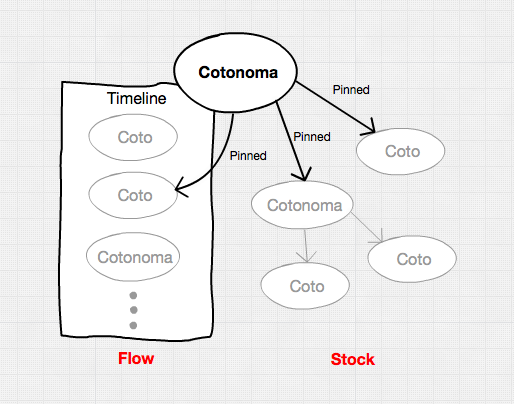
As you can see in the above image, Cotonomas form a recursive structure and each Cotonoma has its own metabolism cycle.
Here you can understand what “Cotonomatization” is. It means converting a plain Coto into a Cotonoma:

I think this process, converting a Coto that has collected many connections and appears to be important into a Cotonoma, in order to create another conceptual space of metabolism, leads to what I originally thought in 2010: “some sort of structure would gradually emerge in the continuous organization”.
I’ve been using Cotoami for more than a year now and feel it works greatly. Many of my Cotonomas have been created spontaneously from my random thoughts or conversations with my friends and they are filled with new discoveries.
I’d like you to try it out if you read this far 😉 There’s a demo server: https://demo.cotoa.me and another server for practical use, which gives accounts to crowdfunders: https://www.patreon.com/cotoami

Piggydb -> Oinker -> Cotoami: We need your help!
Posted: April 4, 2017 Filed under: uncategorized Leave a commentHello!
After the experimental endeavour to create a next-generation Piggydb which became Oinker.me, we decided to re-create it from scratch as open source.
The project is called “Cotoami”. It is still in an early stage of development and we are looking for some comments and feedback from people who are interested in Piggydb-like applications.
You can easily catch up on the history of development by reading the tweets at https://twitter.com/cotoami and try out the latest version at https://cotoa.me
- Cotoami – https://cotoa.me
- Twitter – https://twitter.com/cotoami
- Cotoami GitHub repositories – https://github.com/cotoami
- Cotoami Roadmap – https://github.com/cotoami/cotoami/issues/2

Piggydb V7.0 – Java 8 / New Page Header / Bug Fixes
Posted: February 16, 2016 Filed under: uncategorized 2 CommentsHi there,
It’s long time no see… actually, it’s almost two years since the last version (V6.18) was released.
After the long pause, Piggydb’s new version is finally here.
It doesn’t contain big changes except that the page header has been redesigned. Now it looks cooler than before (hopefully), and the title displayed in the header (“Piggydb Documents” in the screenshot) is the “Database Title” which you can change in the System Info page.
It also fixes a bug that it won’t work offline because of the reference to the hosted Mathjax library.
- Mathjax load from cdn makes Piggydb unusable without internet connetction · Issue #9 · marubinotto/Piggydb
Lastly, Piggydb V7.0 requires Java 8. If you use one of the previous versions of Java, you need to upgrade it.
Enjoy 😉
Knowledge Network Graph Visualization
Posted: October 25, 2015 Filed under: uncategorized 5 CommentsFrom time to time I received requests for MindMap or ConceptMap like graph visualization (nodes and edges style) in Piggydb or Oinker. But I thought there were things to consider in order to implement it since the models in both applications were document-oriented as I explained in an Oinker Blog entry.
- Graph Style (Nodes and Edges) or Document Oriented Style? | Oinker Blog
Recently I came up with an idea and implemented it in Oinker as below:
The problem of displaying document-oriented data in a graph view is that a document tends to contain many large nodes which are not suitable for bird’s eye overview. So we should deal with these nodes somehow to avoid the verbosity of being precise. The idea I came up with is a way to select nodes for a graph. I call these selected nodes “topic nodes“.
Currently a topic node is:
- a node whose content has only one word or sentence.
- a node whose content length is shorter than or equal to 30.
- a node whose content is not Markdown
- a node whose content is not a URL
- a node whose content is not a file
You can check out an example of how topic nodes work in Oinker’s graph view at:
https://oinker.me/room/marubinotto/impact-mapping
This feature is still experimental and waiting for your feedback.
Oinker – https://oinker.me/
Piggydb and Oinker as a Content Publishing Platform
Posted: August 26, 2015 Filed under: uncategorized Leave a commentHi there,
It’s been a while. These days I’m working on a web service “Oinker” off and on, squeezing time from busy days.
Recently, I’ve started pulling well-proven features from Piggydb and adding them to Oinker. One of them is a content publishing capability which is implemented as “Anonymous Access” in Piggydb (sample site).
Oinker’s publishing feature is more sophisticated than Piggydb. You can publish your content on a room basis. A room is like a chatroom in Oinker and it has a chat timeline and a board on which you create content with your roommates.

A room is composed of a timeline and a board
You can make a board open to public so that anonymous visitors can view the content, and additionally allow logged-in users who are non-members of the room to view the timeline and post messages to it. So you can not only publish your content, but also collect feedback from audience.

What kind of content can you create in Oinker? Just check out the sample content: Unknown Tokyo

Oinker is now open beta!
Posted: March 2, 2015 Filed under: uncategorized Leave a commentYou can sign up for free at: https://oinker.me




I’m looking forward to your feedback 😉
What is Oinker?
Posted: January 22, 2015 Filed under: uncategorized Leave a commentI’ve launched a blog to deliver weekly updates on Oinker:
Oinker is now accepting invitation requests!
Posted: December 31, 2014 Filed under: uncategorized Leave a commentHappy new year 2015 from Japan! I hope you have a wonderful year, especially in terms of knowledge work 🙂
As this year begins, the newborn service Oinker starts accepting invitation requests.
As you saw in the movie, Oinker is extremely simple. You just chat alone or with your friends and connect the comments (oinks) by dragging and dropping.
That’s all, but its potential is enormous.
I’ve been using it in real business projects with my colleagues for about a year, mainly for ideation, task and knowledge management, and it’s been just amazing. I’ll write the details of these use cases at the Oinker blog.
The best way to feel the potential is to experience it yourself, so if you are interested in trying it out, please email to support@oinker.me
Oinker beta-test is about to start!
Posted: December 16, 2014 Filed under: uncategorized Leave a commentFinally, this day has come.
As I wrote in last week’s blog post, I’m going to send invitations of Oinker beta-test to the Piggydb Supporters after this post published.
What is Oinker? Just look at the video below:
If you are interested in trying it out, but not a Piggydb Supporter, please consider to buy the Piggydb Supporters Edition or wait for the next phase of inviting beta testers on request basis, which will start in the first quarter of the next year.
You can also get the updates of the service via Twitter: https://twitter.com/oinker_news


Recent Comments