
The Piggydb Way: #2 Tags as First-Class Components
Posted: October 20, 2012 Filed under: essay, thepiggydbway 2 CommentsMost of you who happen to stumble upon piggydb.net are sure to know what you want, I imagine. You are looking for a tool (in the categories like wiki, outliner, personal database, etc) that helps you organize your information in a more effective way as an alternative to, for example, Evernote or Springpad. Then suddenly, I began to talk about the ‘reversal process’ instead of explaining the basic organizing functionality. You might be confused or think you didn’t need it because you knew what kind of information you were going to organize and how to organize it, and you just needed a tool to support it. Well, okay, but is that really the case? Are you really sure you know what you want?
When you are about to collect information and organize it, quite naturally, you know what kind of information you are going to organize, and anticipate the result. It may be information about your project, daily routines, a travel plan, or it may be a diary. You have already prepared the container in which you are going to just place pieces of information one by one. It would be quite straightforward, you think. However, once you begin it, something in you will be stimulated by what you are doing, and sooner or later, you will unconsciously step into the area of Knowledge Creation even with a most primitive container you use, such as a piece of paper.
Let’s suppose that you keep a record of things you have done in your daily life in a plain old paper notebook. You do so because you want to use these information later on when you need to know what you did and when you did it. And then, one day, after a while since it became a daily routine, you reflect on the record. In that reflection, you happen to find an interesting pattern in the log. You underline these places with a red pen and write an explanation of the concept common to them in your own way. This discovery is totally what you didn’t expect when you started this habit. I’m sure many of you have experienced something like this before if you have a note-taking habit. Let’s call this kind of practice ‘Weighting Information‘ (selecting a certain part of information and putting some meaning into it). So you acquired a new point of view as a result of weighting information.
Information weighting appears whenever you deal with information. For example, if you are reading this article on a web browser (I believe most of you are), it must have a bookmarking function. Bookmark allows you to save addresses of websites that you want to revisit later, and it can be regarded as a way of information weighting. You select a small bit of the vast sea of the Web and attach the concept of ‘bookmark’ to it.

As you may have noticed in the example of recording things done, there are two steps in information weighting. The first one is the discovery of an interesting commonality across random things and the second one is putting a label on it. In this process, the mechanism of the discovery is especially interesting and mysterious. One of the most interesting things about it is that you can’t expect the outcome in advance, in other words, you can’t plan what kind of thing you are going to discover.
The other day, I came across an interesting column on innovation titled “The Idea Idea” by Peter J. Denning (http://cs.gmu.edu/cne/pjd/PUBS/CACMcols/cacmMar12.pdf). Denning brought skepticism to the popular belief that an innovation is the result of adopting a good idea. He proposed a hypothesis that “practices rather than ideas are the main source of innovation” and “many ideas are therefore afterthoughts to explain innovations that have already happened“. The term ‘idea‘ here can be replaced by ‘concept‘ that we are discussing about. In the above example of information weighting, the concept discovery was not expected or planned but happened in the course of the practice of recording things done in daily life.
Stephen King, a world-renowned novelist, once wrote about his style of writing novels. He wrote in his memoir “On Writing” as follows: “I distrust plot for two reasons: first, because our lives are largely plotless, even when you add in all our reasonable precautions and careful planning; and second, because I believe plotting and the spontaneity of real creation aren’t compatible.” The ‘plot‘ mentioned in the quote would correspond to the ‘idea‘ in Denning’s column. As Denning said practices are the main source of innovations and ideas are afterthoughts to explain innovations that have already happened, King said stories pretty much make themselves in the course of writing and progress to theme. And King’s figurative expression for his creative process is really impressive: “stories are found things, like fossils in the ground“. Although I don’t know of many novelists, I imagine there are not a few novelists who take this type of approach. Haruki Murakami, who reportedly leads race for Nobel prize for literature as of writing this article (the winner turned out to be Mo Yan who happens to have the same family name as my wife), is one of them. This spontaneity would be essential for creative process and I think that human beings instinctively know it because, as King wrote, “stories are relics, part of an undiscovered preexisting world”
After discovering a concept, you need to put a label on it so that it can be a part of your knowledge. And through this label, you can view the world around you in a fresh-new viewpoint. This kind of concept-oriented knowledge building is the main focus of the Knowledge Creation in Piggydb.
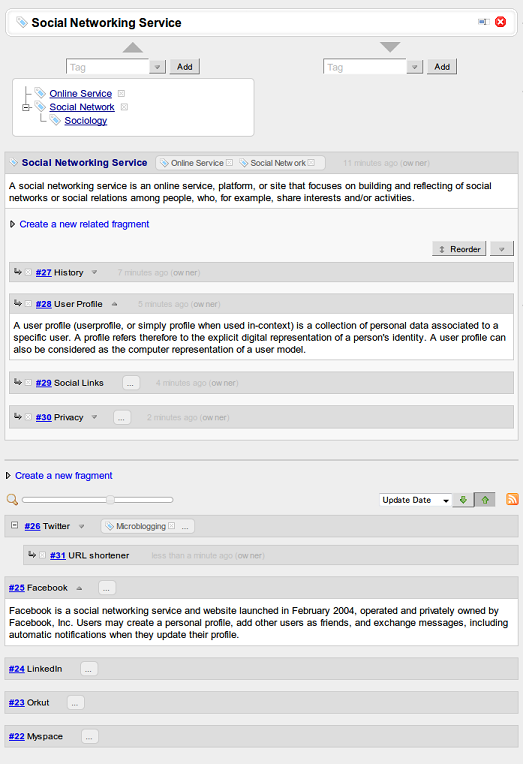
The most important feature of Piggydb in terms of concept-oriented knowledge building is Tag-Fragments. A tag-fragment, which is the kind of a knowledge fragment whose ‘as-a-tag’ attribute is enabled, can be used to represent a concept that you have discovered as in the above episode or selected as a theme in advance for your study or investigation. Originally, classic tags have played an assistant role in the Web 2.0 systems providing a lightweight way of organizing information. And, of course, you can use these tags to represent found concepts other than familiar categories. However, this means just grouping elements by concepts, which does not contain any structure for the concepts.

As you might know already, the labels of concepts themselves do not solely hold the value of your knowledge. They are just labels. The value resides in the context behind concepts, the context in which you have come to discover and build the concepts (the Internet is filled with fruitless communication triggered by responding to keywords without considering their contexts). Therefore, the important factor deciding the value of your concepts is how you structure this context information, and that’s why Piggydb introduces Tag-Fragment that supports two-layer structure allowing you to evolve found concepts into more rich and structured knowledge. While classic tags is no more than collective keywords for indexing, Piggydb’s tags can be treated as the same as the first-class information components (knowledge fragments) in a database, which means they can have their description and relationships to other components.
[To be continued]


As tag structures become more complex, it would make sense to be able to share them with other tools. Conversely, I have a complex hierarchical structure of a few hundred tags that I would like to import into Piggydb. Is there or will there be a way to import/export tag structures in a format such as tab indented text or OPML? I have found these to be the most popular generic formats for transfering outline information.
Hi Alexander,
Yes, I’ve been thinking about this. Importing via a simple format would be a good start to support these capabilities. Tab indented text for tags seems great, so I will experiment it in the coming versions. Thank you for your suggestion!