
Oinker is now open beta!
Posted: March 2, 2015 Filed under: uncategorized Leave a commentYou can sign up for free at: https://oinker.me




I’m looking forward to your feedback 😉
What is Oinker?
Posted: January 22, 2015 Filed under: uncategorized Leave a commentI’ve launched a blog to deliver weekly updates on Oinker:
Oinker is now accepting invitation requests!
Posted: December 31, 2014 Filed under: uncategorized Leave a commentHappy new year 2015 from Japan! I hope you have a wonderful year, especially in terms of knowledge work 🙂
As this year begins, the newborn service Oinker starts accepting invitation requests.
As you saw in the movie, Oinker is extremely simple. You just chat alone or with your friends and connect the comments (oinks) by dragging and dropping.
That’s all, but its potential is enormous.
I’ve been using it in real business projects with my colleagues for about a year, mainly for ideation, task and knowledge management, and it’s been just amazing. I’ll write the details of these use cases at the Oinker blog.
The best way to feel the potential is to experience it yourself, so if you are interested in trying it out, please email to support@oinker.me
Oinker beta-test is about to start!
Posted: December 16, 2014 Filed under: uncategorized Leave a commentFinally, this day has come.
As I wrote in last week’s blog post, I’m going to send invitations of Oinker beta-test to the Piggydb Supporters after this post published.
What is Oinker? Just look at the video below:
If you are interested in trying it out, but not a Piggydb Supporter, please consider to buy the Piggydb Supporters Edition or wait for the next phase of inviting beta testers on request basis, which will start in the first quarter of the next year.
You can also get the updates of the service via Twitter: https://twitter.com/oinker_news
A whole new web service ‘Oinker’ coming soon!
Posted: December 11, 2014 Filed under: uncategorized 6 CommentsHi there,
It’s been another break in developing Piggydb for almost a year. It was probably the longest but I believe the most important pause ever in this project.
I’ve been working on a new web service that shares many concepts with Piggydb, and finally, it’s about to enter the phase of inviting beta testers.
I’m going to start with invitations for Piggydb Supporters to join the first group of beta testers.
Stay tuned!
![]()
Another thoughtful comment on filters
Posted: November 19, 2014 Filed under: uncategorized Leave a commentAnother thoughtful comment on filters from Igor:
I am tinkering a bit with Piggydb, as I am looking for a replacement for BasKet which stalled at KDE3, and my favorite Wiki on a Stick that is on its way to discontinuation of development for some years now (unfortunately, pretty common in one-man-developement FOSS). So far, Piggydb looks extremely promising. To get to know it, I wrote a little knowledge base of its user interface, parts of which are undocumented, and that made me read the documentation base thoroughly.
Concerning redundancy of filtering, I can only confirm it from the standpoint of purity of concept. However, Piggydb is just a tool, so the true concept is its projected usage. I see filters as saved searches, and when the base is growing huge, one needs every help in finding fragments. Using tags, that is, concepts for this purpose makes tags themselves impure, or rather misused. Besides, no matter how do we approach tagging, possibility of tagging overflow is luring all the time, the more so as one pays more attention to structuring one’s knowledge base. We learn about it from almost any science, particularly from humanities, as the extent of conceptual superstructure might seriously challenge any basic influx of data, and the literary criticism is a very good example.
So, the only thing I feel is wrong with filters is impossibility of filtering by keywords. In other words, I’d like to see the filtering tool as another search tool with additional naming and saving. This, of course, can be an option added to the main search tool.
As for the third, the left frame or column, in the beginning it seemed to me as wasting of precious page space, once there is this very fine quick preview available. But I very soon learned to appreciate the possibility of viewing simultaneously entire single fragment and the list of other ones. Particularly in the initial phase of looking for regularities it is good to have as few limitations as necessary. So I’d prefer not having the list (or the tree) in the central frame automatically filtered by the chosen fragment tags, because instead of sparing few clicks it is often forcing few extra. I am regularly comparing the fragment to various sets of other fragments, so I am doing some searching in the central frame, having the focused fragment exposed in the left one. Of course, when one already knows one’s base hierarchy and has it built, then present behavior is perfectly OK, but as I got it, Piggydb is about finding a structure rather than documenting it, and about relation network rather than hierarchical tree.
Actually, the only thing I believe Piggydb is missing at this moment is graphical, vectorial presentation of relations network on demand, with fragments represented by their names (possibly links) interconnected by arrowed lines, maybe some sort of SVG. It would make a huge help in examining (and possibly even editing?) already established relationships. But again, bearing in mind probable number of fragments of any serious base, I am fully aware this might be too much to ask for. Pity, because this one feature would make Piggydb a killer app.
Piggydb V6.18 – All/Any Switch for Tag Search and Related Fragments
Posted: March 30, 2014 Filed under: uncategorized 3 CommentsThis release adds yet another update to the search feature by adding an All/Any switch to the tag search:
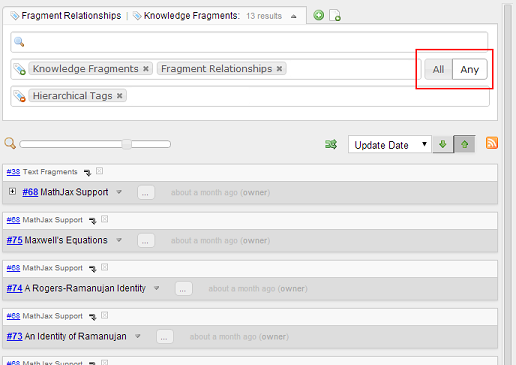
In the previous versions, searching by tags results in the fragments tagged with ‘all’ of the specified tags. From this version, you can switch between ‘all’ and ‘any’. ‘Any’ displays the fragments tagged with ‘any’ of the specified tags.
The ‘Any’ tag search produces another feature called “related fragments”. In the fragment page, the list view displays all the fragments tagged with any of the tags of the focused fragment:
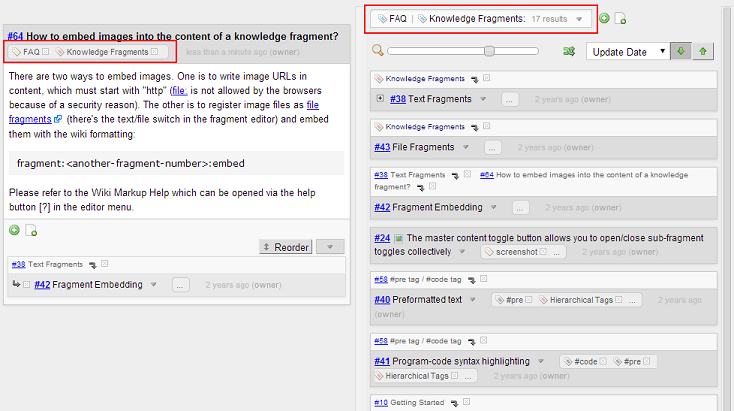
You can download the latest version from: https://sourceforge.net/projects/piggydb/files/latest/download
How to install PiggyDB on a Raspberry PI
Posted: March 25, 2014 Filed under: media article Leave a commentI’ve stumbled upon an interesting article about Piggydb with the title above:
How to install PiggyDB on a Raspberry PI
– https://medium.com/p/396fb2892bb6

The description of Piggydb in the article is concise and to the point.
If you don’t know PiggyDB yet, go have a look. To make it short, it’s your personal wikipedia. You can tag fragments (= an article), upload pictures or files, use its search engine to find what you stored in here. The smaller your fragments are, the better I think. Main features I forgot to speak about : Zero setup and it’s web application (Nothing to install anywhere else!).
Get Supporters Edition at CeBIT!
Posted: March 6, 2014 Filed under: uncategorized Leave a commentWe decided to give all of CeBIT talk attendees free copies of the Piggydb Supporters Edition which provides premium features in addition to the standard features.
We hope you’ll come to Piggydb’s talk in Hanover next week!
http://www.cebit.de/event/grow-your-knowledge-with-piggydb-/VOR/57737
Piggydb at CeBIT 2014 in Hanover
Posted: February 25, 2014 Filed under: uncategorized 3 Comments“Grow Your Knowledge with Piggydb” by Dmitri Popov
– 10 Mar. 2014, 01:00 PM – 01:45 PM
– http://www.cebit.de/event/grow-your-knowledge-with-piggydb-/VOR/57737
Don’t miss it if you will be at CeBIT! It’s a very rare opportunity to hear about Piggydb.


Recent Comments